カテゴリー: 開発日誌
はじめに
皆さんは機械学習やデータ解析をする際に何から着手しますか?
おそらく経験のない方は何から始めれば良いかわからなかったりするかと思います。
その答えの一つとしてAWS SageMaker Canvasを提案しようと思います。
今回はSageMaker Canvasについて
・使用感
・どの程度の予測精度が出るのか?
をお伝えできたらと思います。
目次
- 機械学習の事前知識
- SageMaker Canvasとは
- 予測精度の検証対象について
- 料金形態
- SageMaker Canvasの使用手順・結果
- まとめ
機械学習の事前知識
機械学習の分野を扱うため、初学者でも読みやすいよう簡単に説明します。
機械学習にはいくつか種類があります。今回対象とするのは最も一般的な「教師あり学習」と呼ばれるものになります。
教師あり学習というものは機械に対して学習データと正解のセットのデータ(データセット)を学ばせます。
この機械をモデルと言います。学習が終わったモデルを学習済みモデルということもあります。
学習済みモデルが手に入ったら、そのモデルに対してデータを入力することで、予測結果を得ることができます。
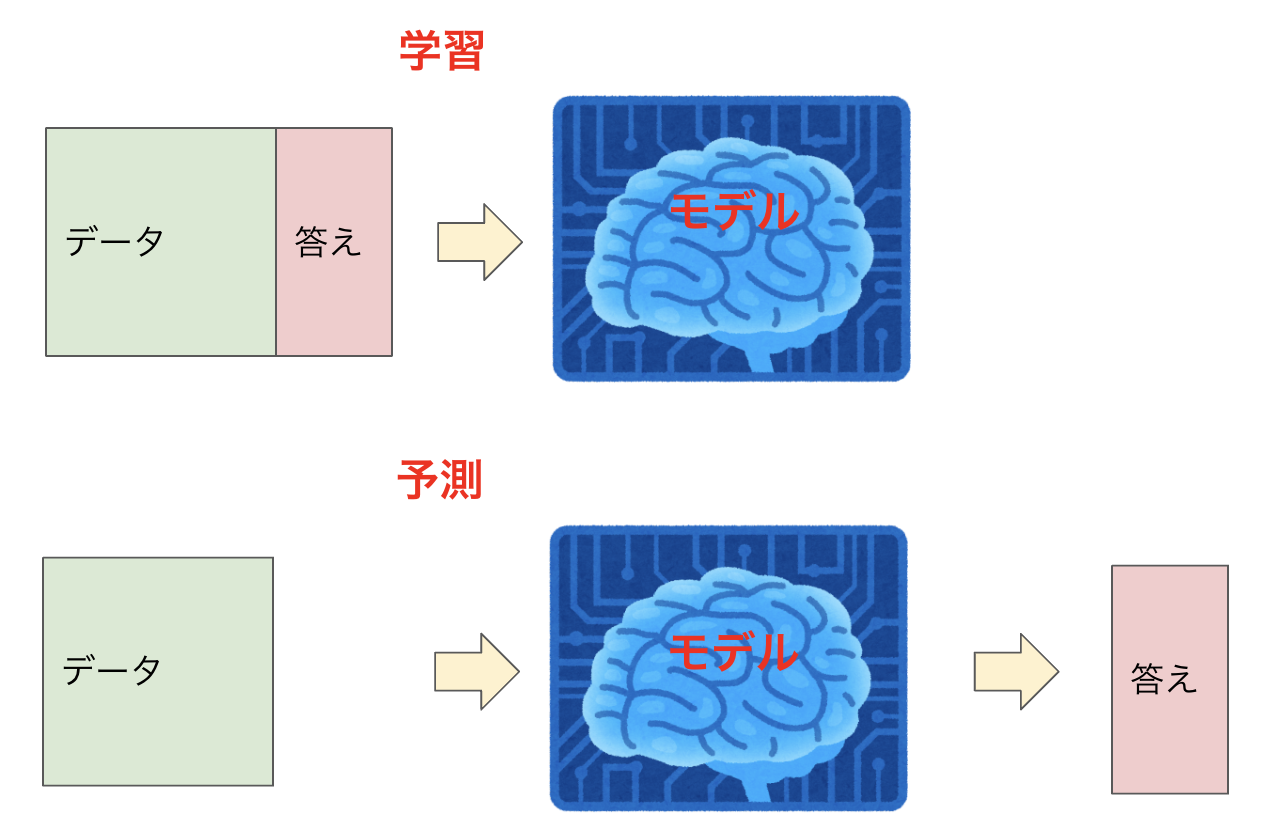
例えば、スーパーマーケットの曜日や立地などのデータと当日来客数(答え)がある場合、それらを使用し、学習モデルを作成します。
その学習モデルを使用し、曜日や立地などのデータから未来の来客数を予測することができます。
ざっくりとした機械学習の説明は以上になりますが、実際にはデータ作成やモデル選定・策定などもっとやることは多く、特にデータの作成・加工には特徴量エンジニアリングといった一学問があるくらい深いものとなっております。
SageMaker Canvasとは
今回使用するSageMaker CanvasはノーコードでGUIでモデルを作成し予測を得られる※AutoMLサービスです。
本来機械学習に取り組む際には特徴量エンジニアリングをはじめとした様々な知識・技術が必要となります。
これらの知識がなくとも簡単にデータ解析やモデル作成を行えるサービスとなっています。
初学者はもちろん、機械学習に慣れている方でも初動のアプローチとして利用することで、開発工程の短縮が望めます。
※AutoML:機械学習を現実の問題に適用するプロセスの自動化、データからモデルを構築するプロセスの自動化などを目的とした技術
予測精度の検証対象について
予測精度の検証には機械学習のコンペティションプラットフォームで最も有名なKaggleのチュートリアル「Titanic - Machine Learning from Disaster」を使用します。
データが揃っているのと、チュートリアルであるものの、ある程度人が考えないといけないくらい難易度が高いため、良いベンチマークになるかと思います。
興味がある方はご自身で試してみることをオススメします。
日本語で解説しているサイトも多いので、機械学習の導入としてはベストの課題ですので。
このコンペティション内容としましては映画にもなっているタイタニックの乗員データからそれぞれの生死を予測するといったものになっております。
データの中には性別やチケットのクラスなどがあり、映画を観た方なら分かると思いますが、女性や子供、チケットのクラスが高いお金持ちの人ほど助かる可能性が高いです。
実際にチュートリアルを行う際は上記のようなことを考察しながらデータを見ていき、データを加工したり、モデルを調整します。
今回使用するSageMaker Canvasがどこまでこのような考察を自動でやってくれるかが見所となります。
料金形態
SageMaker Canvasはコンソールの利用時間とデータの大きさによって従量課金されます。
・コンソール利用時間
SageMaker Canvasを利用した時間に応じて下記料金が発生します
$1.9/hour
SageMaker Canvasをログアウトするまでセッションが続くので使い終わったらさっさとログアウトしましょう。
・データの大きさ
トレーニングしたデータの大きさに応じて下記料金が発生します。
|
Number of cells |
Price |
|
First 10M cells |
$30 per million cells |
|
Next 90M cells |
$15 per million cells |
|
Over 100M cells |
$7 per million cells |
例えば10カラム×1000行のデータの場合
10000cellとなるので下記のようになります。
10000/1000000 = $0.3
なお、最新の料金形態についてはAWSのHPを確認してください。
HPには記載されていないですが、モデルの学習か予測の際にインスタンスを使用しているようで、その料金も発生します。
かかっても数時間程度の起動時間なのであまり気にしなくて良いかもしれませんが、一応ご注意ください。
また、無料枠も存在するので試しやすいのも良い点です。
参考:https://aws.amazon.com/jp/sagemaker/canvas/pricing/
SageMaker Canvasの使用手順・結果
事前作業として、Kaggleのアカウントを作成し、Titanicコンペティションのデータセットを取得しておいてください。
Kaggleのアカウントを作成後、Titanicコンペティションに遷移し、参加します。
その後、タブ「Data」の右下にあるDownload Allからダウンロードできます。
1.新規ユーザー作成
SageMaker Canvasを使用するためにはまずユーザーを作成する必要があります。
SageMaker のコントロールパネルへアクセス後、「ユーザーを追加」を押下し、すべてデフォルトのままで構わないのでユーザー作成をしてください。
上記のようにユーザーが追加されるかと思います。
2.SageMaker Canvasの起動・新規モデル作成
作成したユーザーの右側の三角マークを押下し、「Canvas」を押下してください。
しばらくするとコントロールパネルが表示されます。
初期画面だと登録されているデータセットが表示されます。
左のメニューより、モデルとデータセットの選択が可能です。
まず、モデルを作成しましょう。「Models」を押下してください。
「New model」より、新しいモデルを作成することができます。
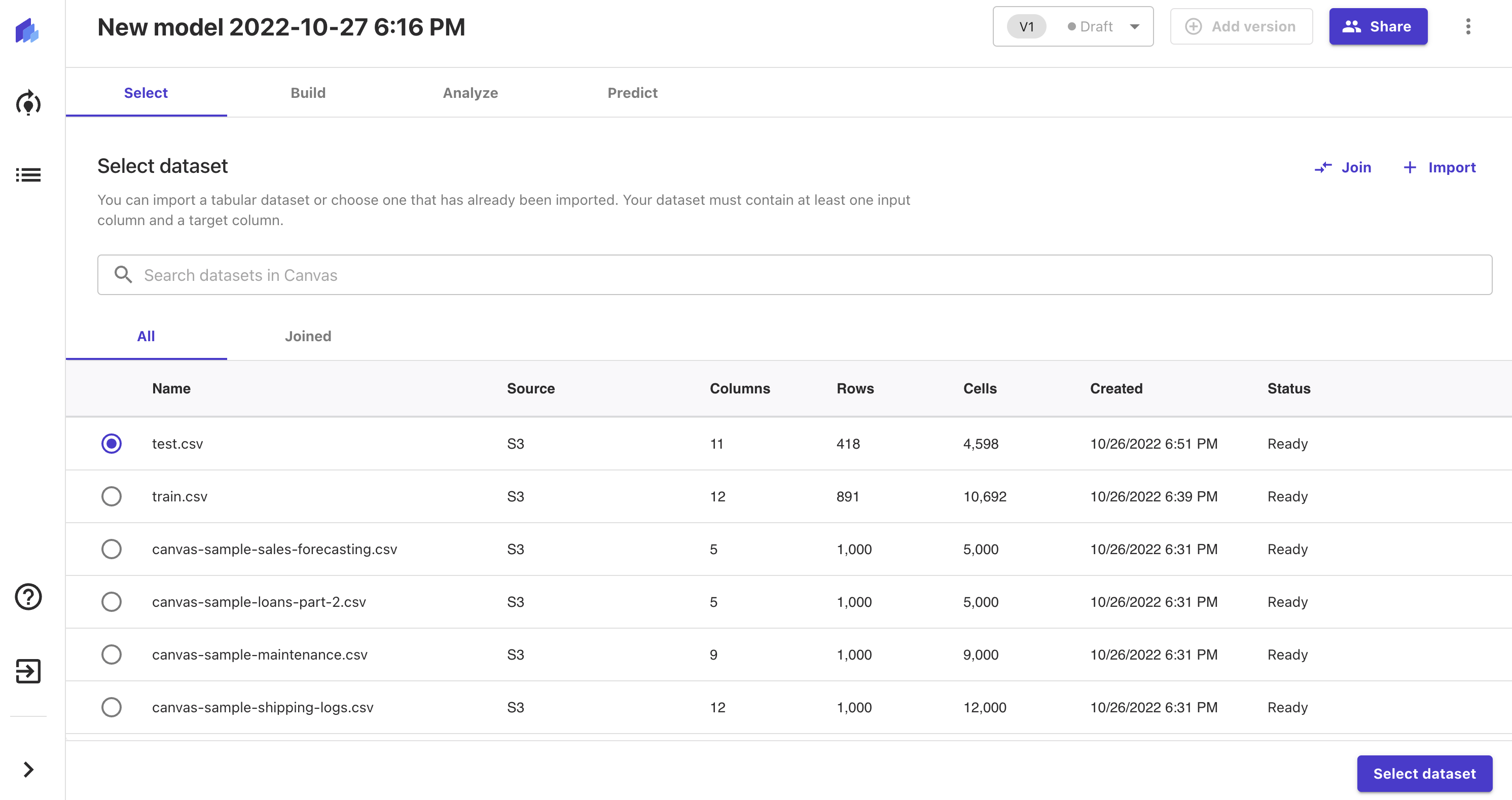
3.データセットの登録・設定
SageMaker Canvasではデータセットを登録する際、ローカル環境から直接アップロードできるようなのですが、手順が複雑だったので、今回はS3にアップロードするようにします。
新しいS3バケットを作成し、事前作業で取得しておいたTitanicコンペティションのデータセットを保存してください。
その後、「Import」ボタンを押下し、
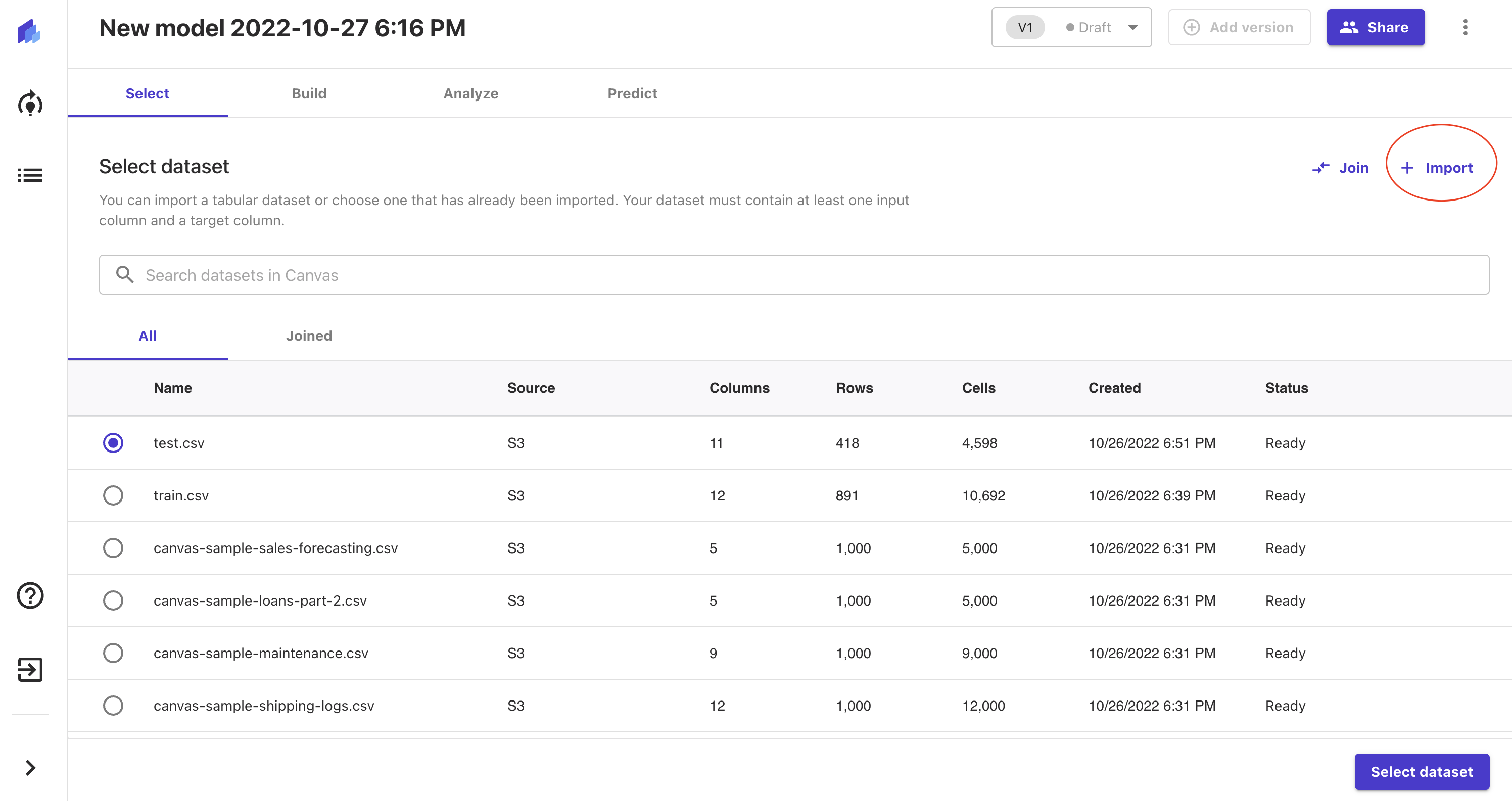
Import画面から先ほど作成したS3バケットを選択します。
バケット内にはデータセットが入っているかと思います。
train.csvを選択し、「Import data」を押下してください。
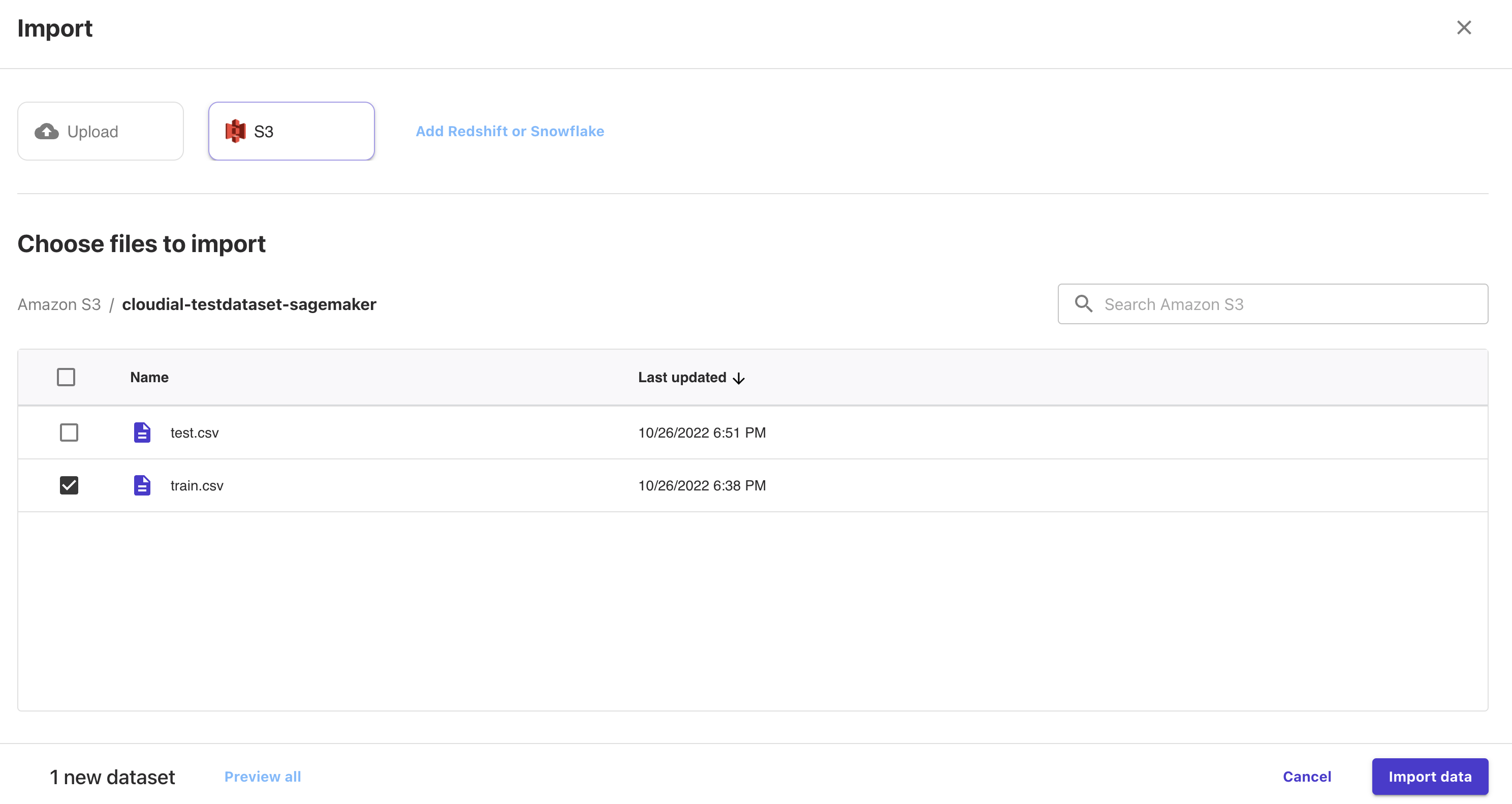
これでSageMaker Canvasにデータセットが登録されました。
test.csvも同様に登録しておいてください。
次はモデルの学習データとして先ほど設定したtrain.csvを使用するよう設定します。
test.csvを選択し、「Select dataset」を押下してください。
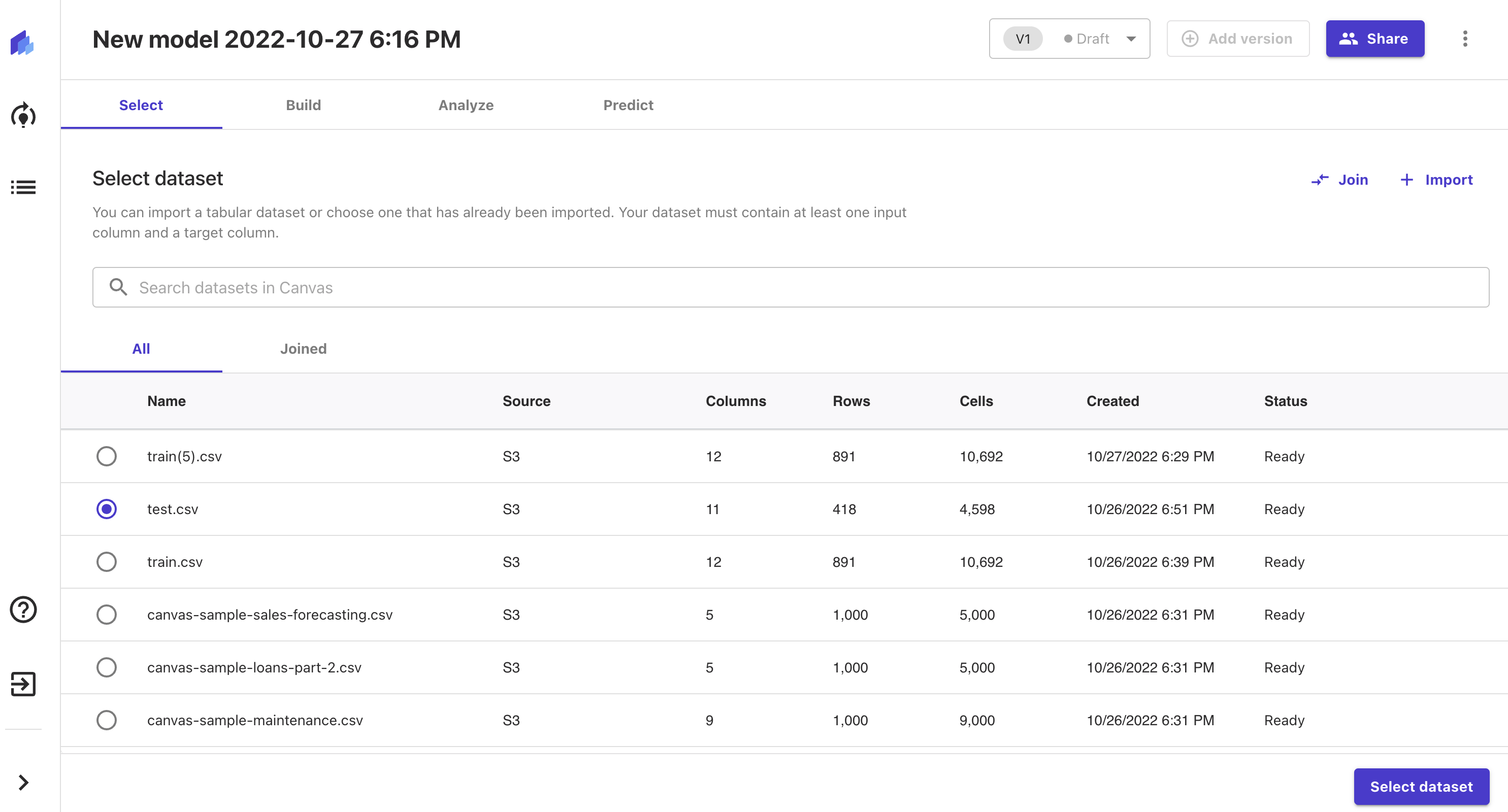
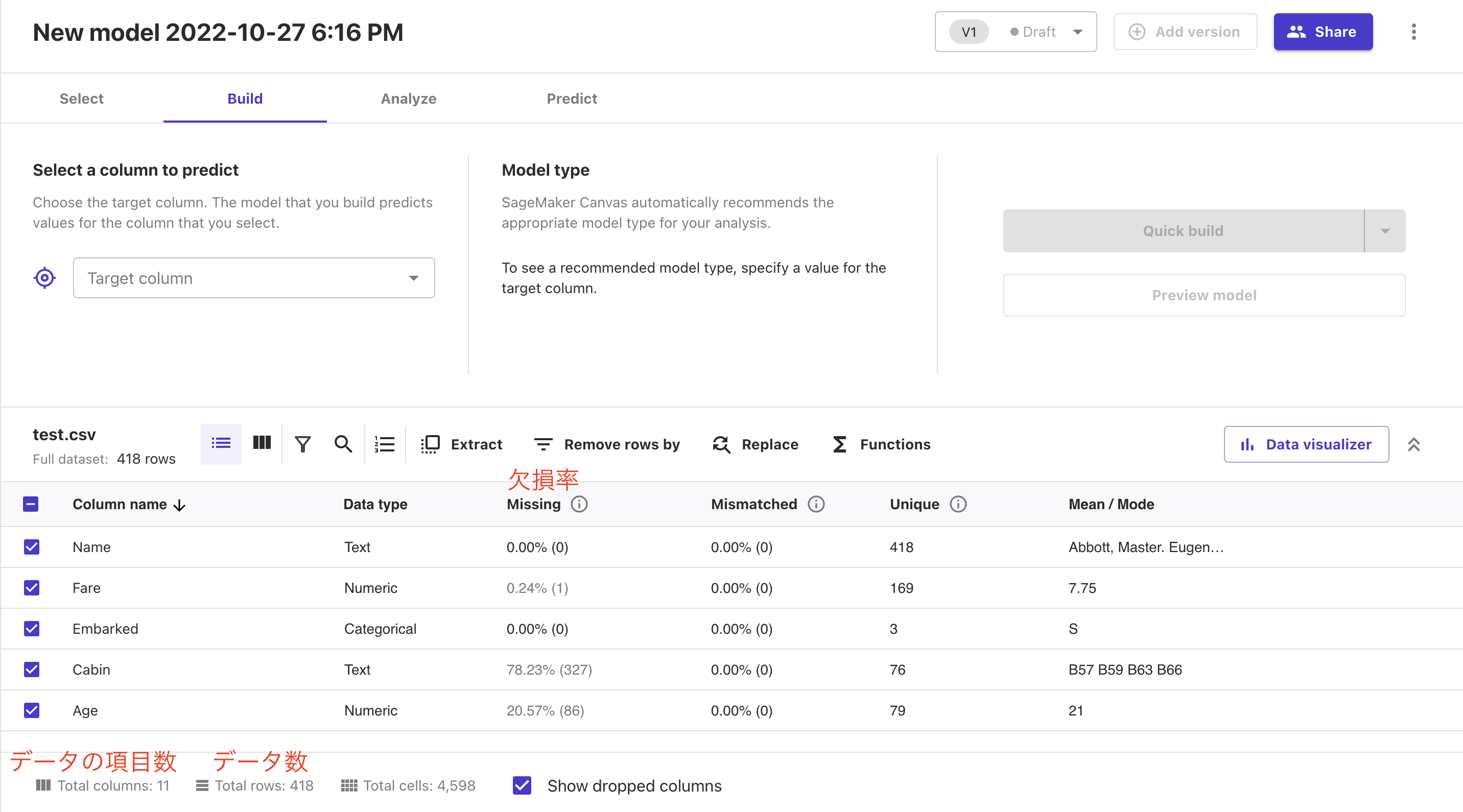
下記のように選択されたデータの情報が表示されます。
データの項目数・データ数ががどれだけあるか?
また、※データの欠損率までわかります。
※得られるデータは必ずしも完全なデータであるわけではありません。機械学習ではこれらの欠損したデータを適切に修正・保管する必要があります。
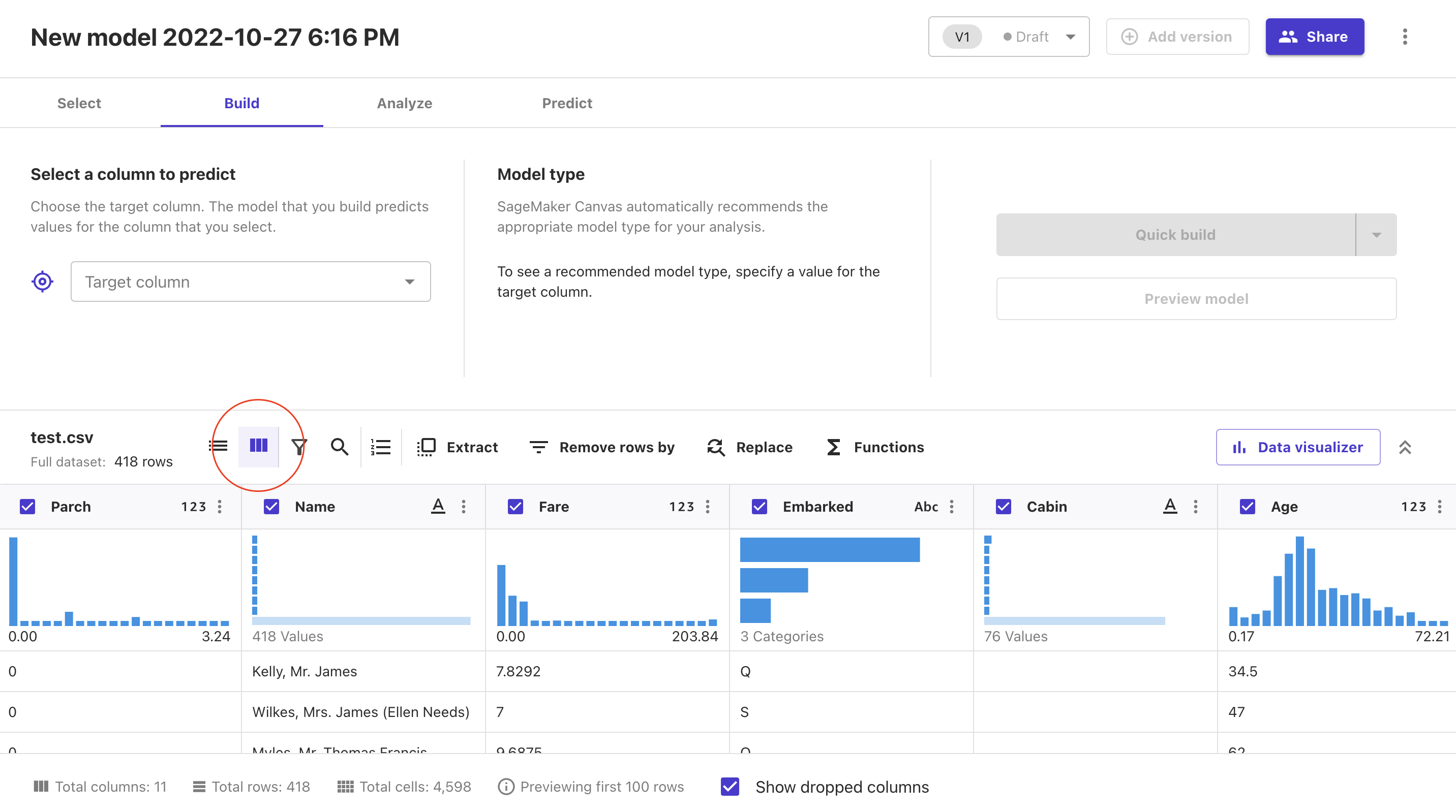
特に下記の赤丸部分を押下すると各種データがグラフ化されます。
この時点である程度どのようなデータなのか見ることができます。
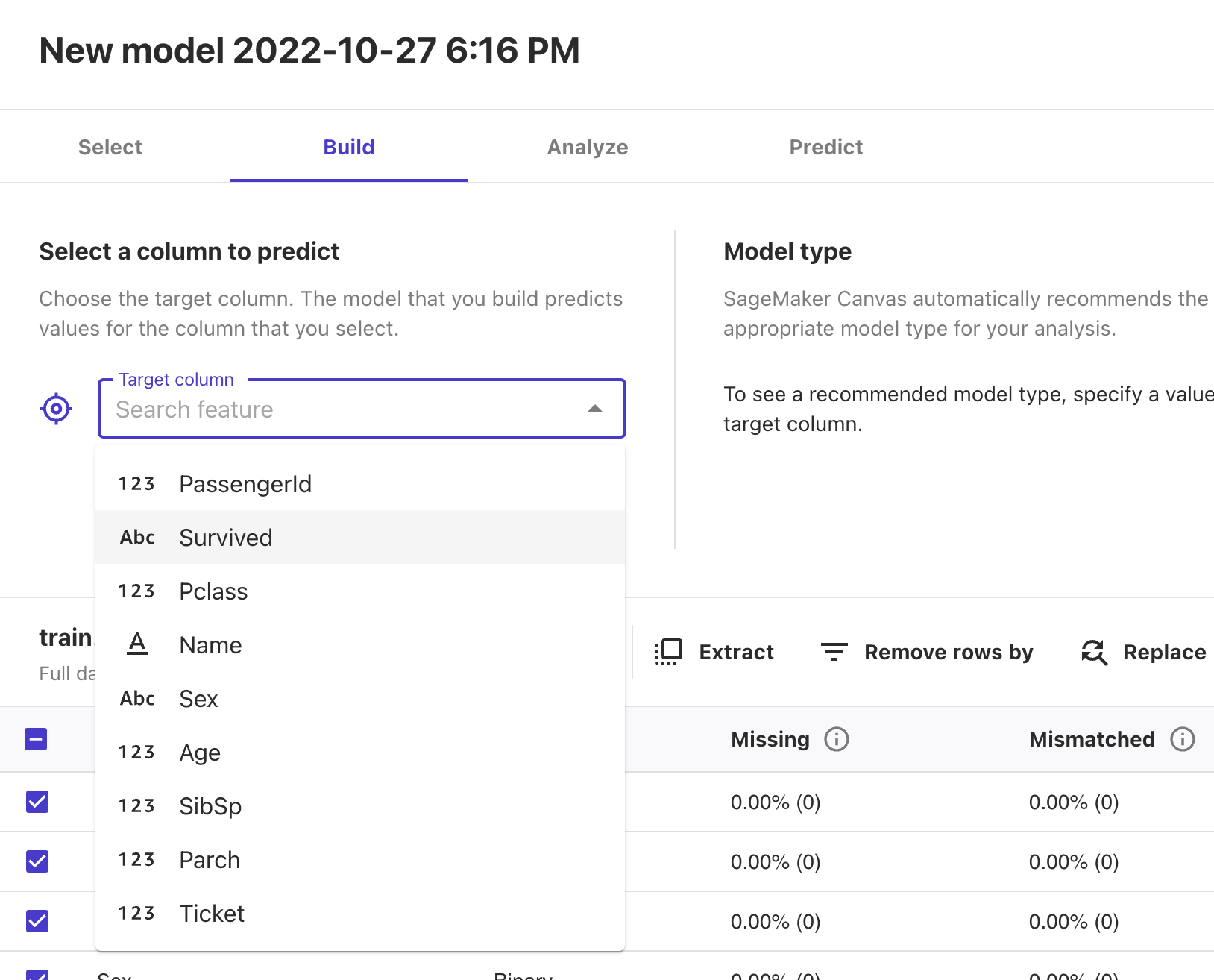
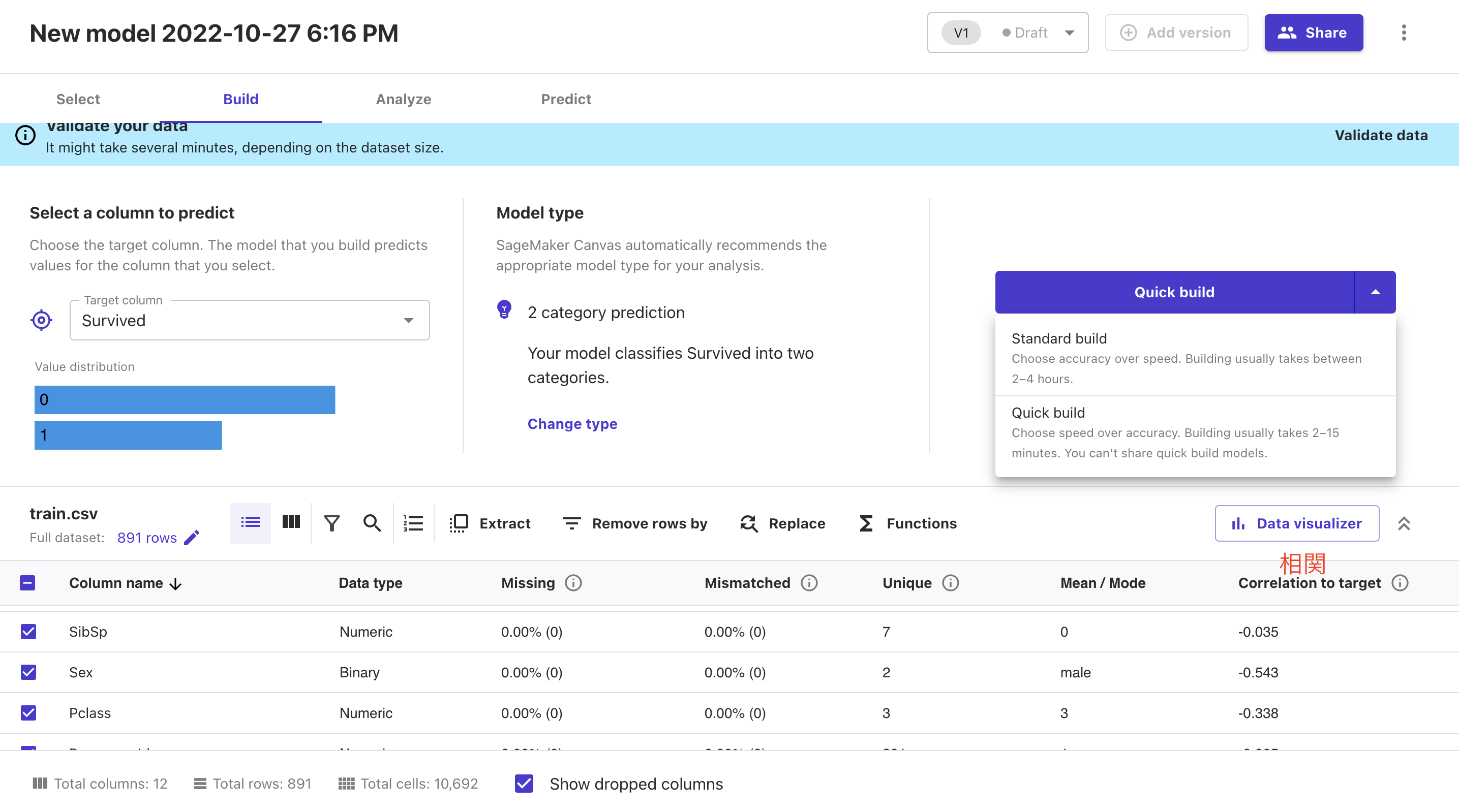
データのなかで今回の答えとなるカラムを選択しましょう。
Target columnの中からSurvivedを選択してください。
Target columnを選択すると、それぞれのカラムとTarget columnとの相関が表示されるようになります。
この時点である程度相関がなさそうなものに関しては学習対象から外してしまっても良いです。
今回は何も外さずに進めていきます。
4.モデルの学習
データが揃いましたので、モデルの学習を開始します。
Quick buildの右側にある三角マークを押下すると
・Standard build:モデル作成をする。実行時間が結構かかります。
・Quick build:高速でモデル作成をする。Standard buildを行う前のチェックとして使用する。
が表示されますが、両方とも試してみてください。
今回の説明ではQuick buildを選択し、実行します。
Quick buildは数分、Standard buildは数時間かかります。
モデルの学習が完了したら、下記のような画面に遷移します。
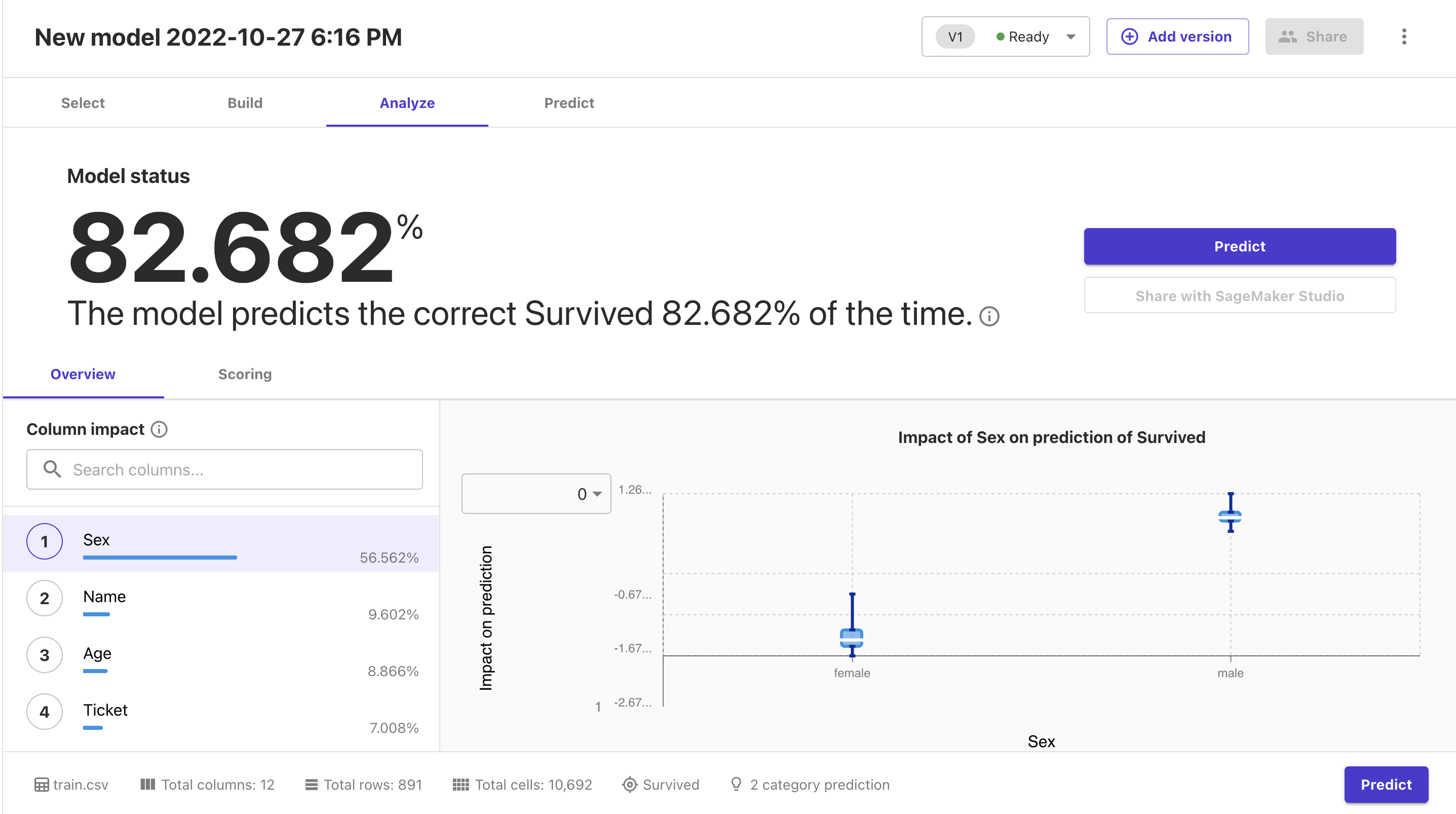
Quick buildでも学習時点での精度は82%出ていますね。良いと思います。
また、学習の中で重要視したカラムも左下にランキングで表示されるのですが、1番目に性別(Sex)が上がっているのも大変良いですね。
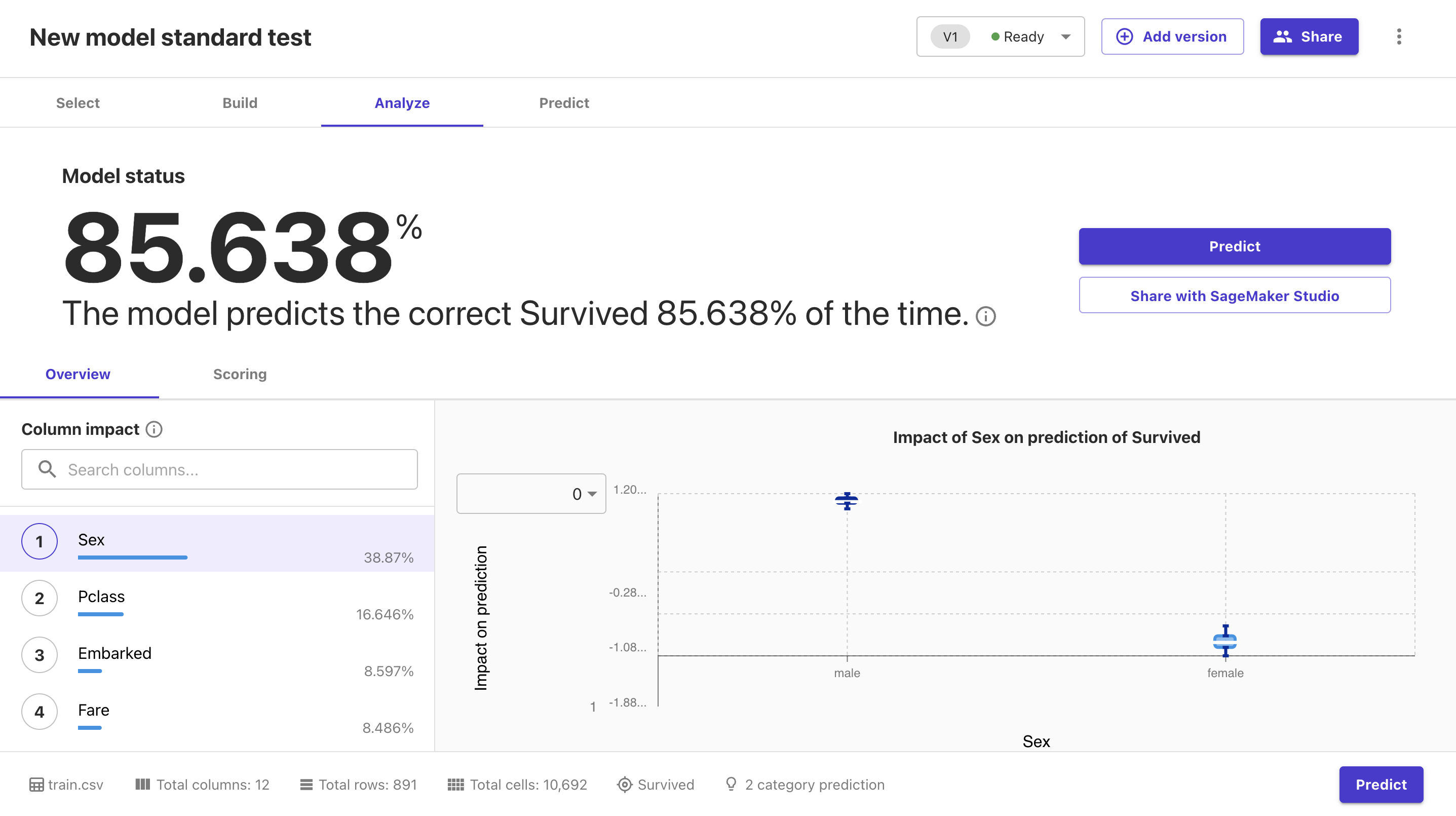
Standard buildで試した結果は下記のようになります。
さらにチケットのクラス(Pclass)もランキングトップに上がってきました。
タイタニックについて知っている人が重要だと挙げそうなカラムが上位に来ているのは驚愕です。
SageMaker Canvasにはデータしか与えていないにもかかわらず、これだけの結果が得られてしまうのはすごいですね。
Scoringを押下するとグラフで確認することができます。
正答率がどうなっているか視覚的にわかりやすいのはGoodですね。
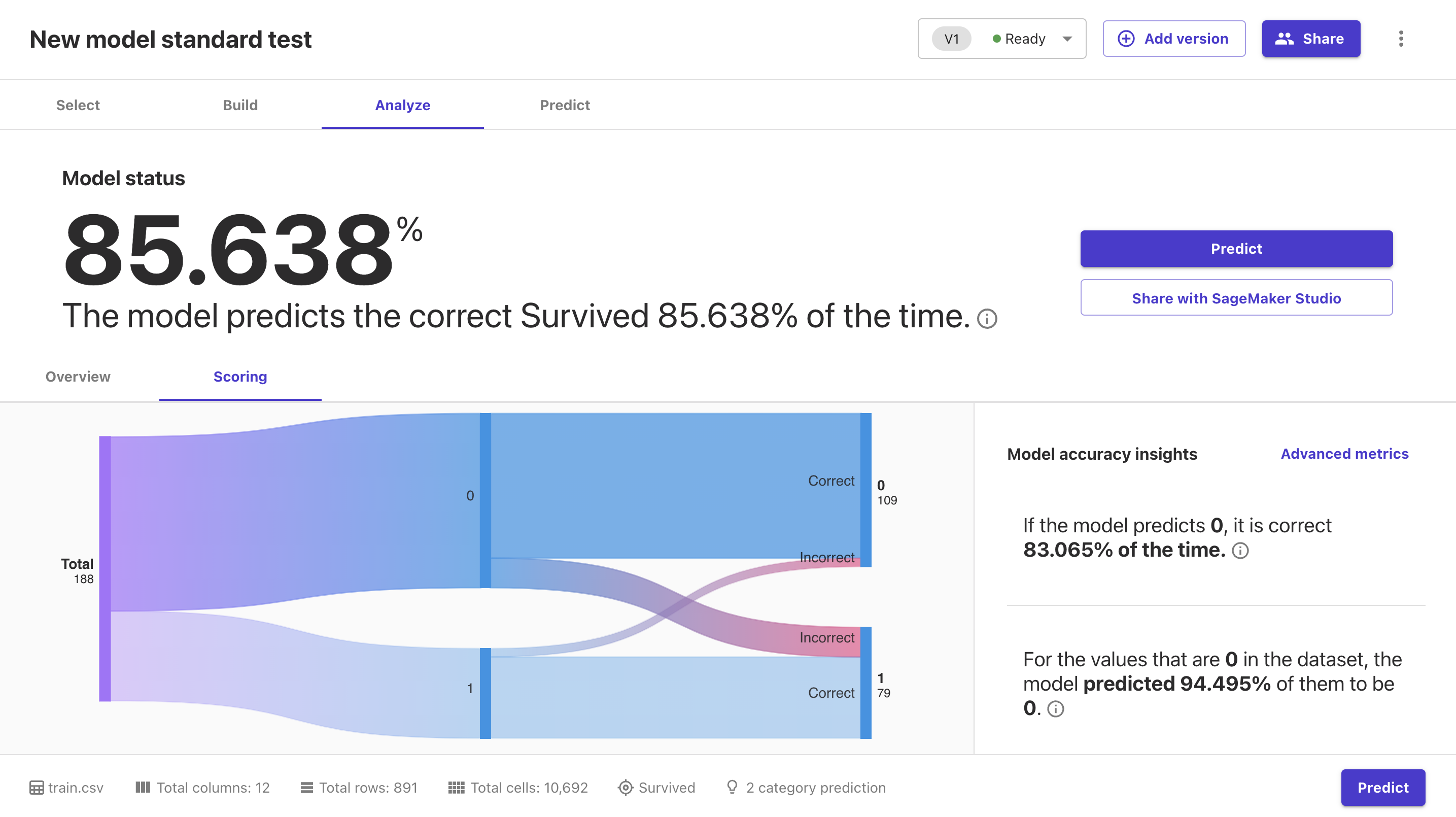
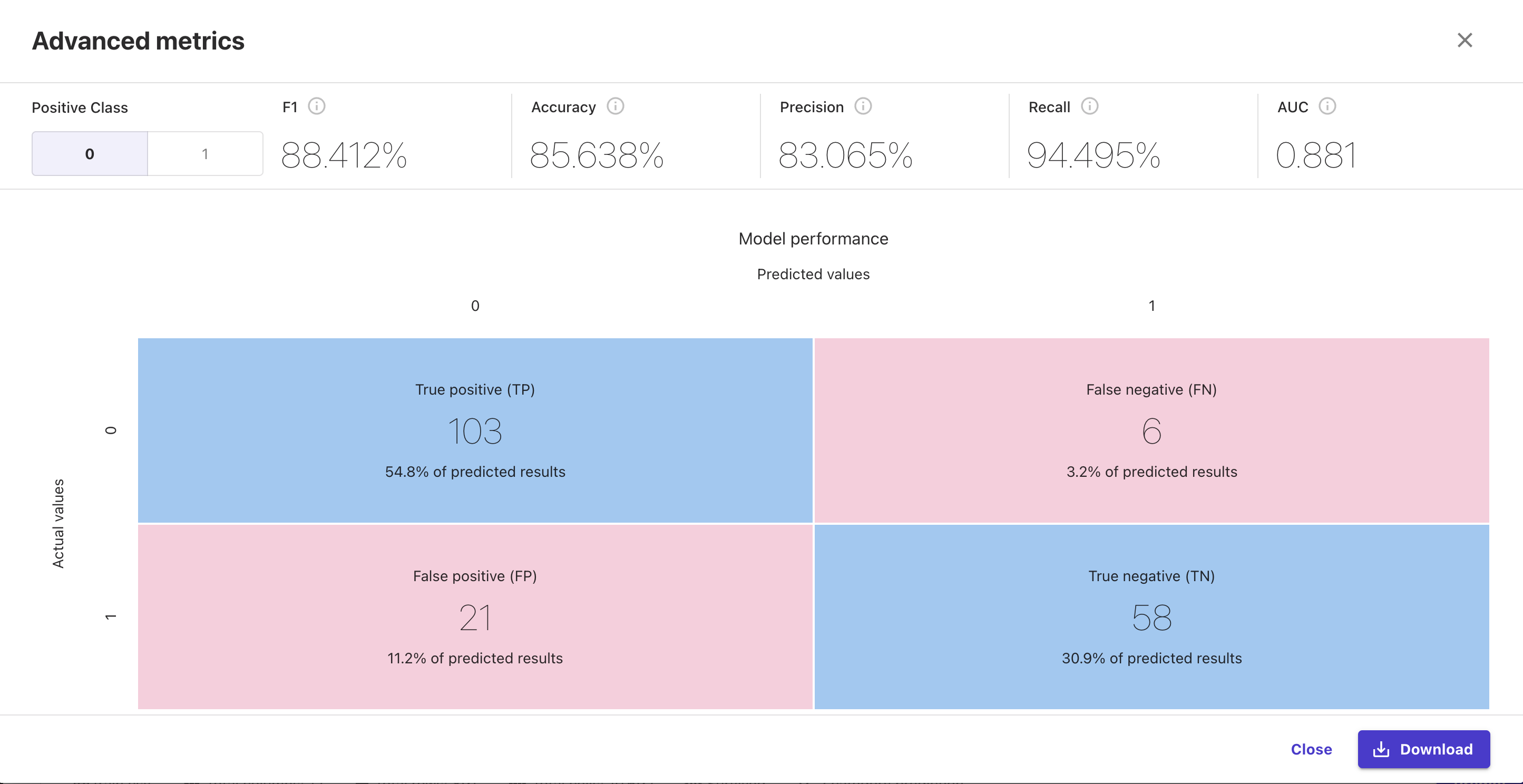
特にAdvanced metricsを押下すると下記のようにさらに詳細な情報を得ることができます。
F1値やAccuracyなどが一発で分かるのはほんとありがたいです。
5.モデルの予測
最後にモデルによる予測を行います。
「Predict」を押下すると下記画面に遷移します。
「Select dataset」を押下してください。
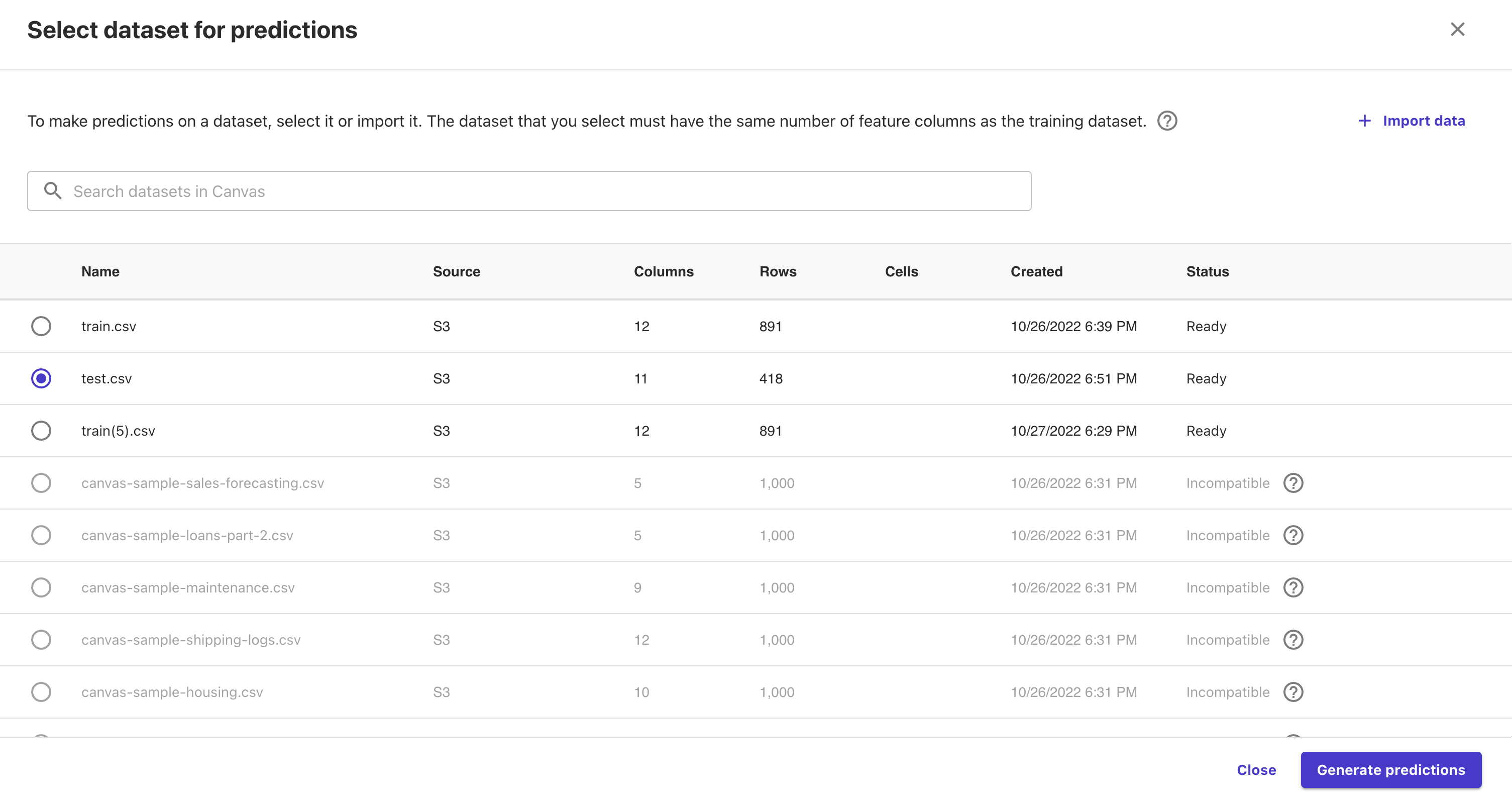
test.csvを選択し、「Generate predictions」を押下すると予測が開始します。
予測が完了するとStatusがReadyになります。
右側にある点を押下し、Downloadを選択してください。
予測結果のcsvデータが得られます。
これが機械学習において得たかったデータになりますね。
csvの中身は下記のようになっており、予測値(probability)と回答(今回はSurvived)が得られます。
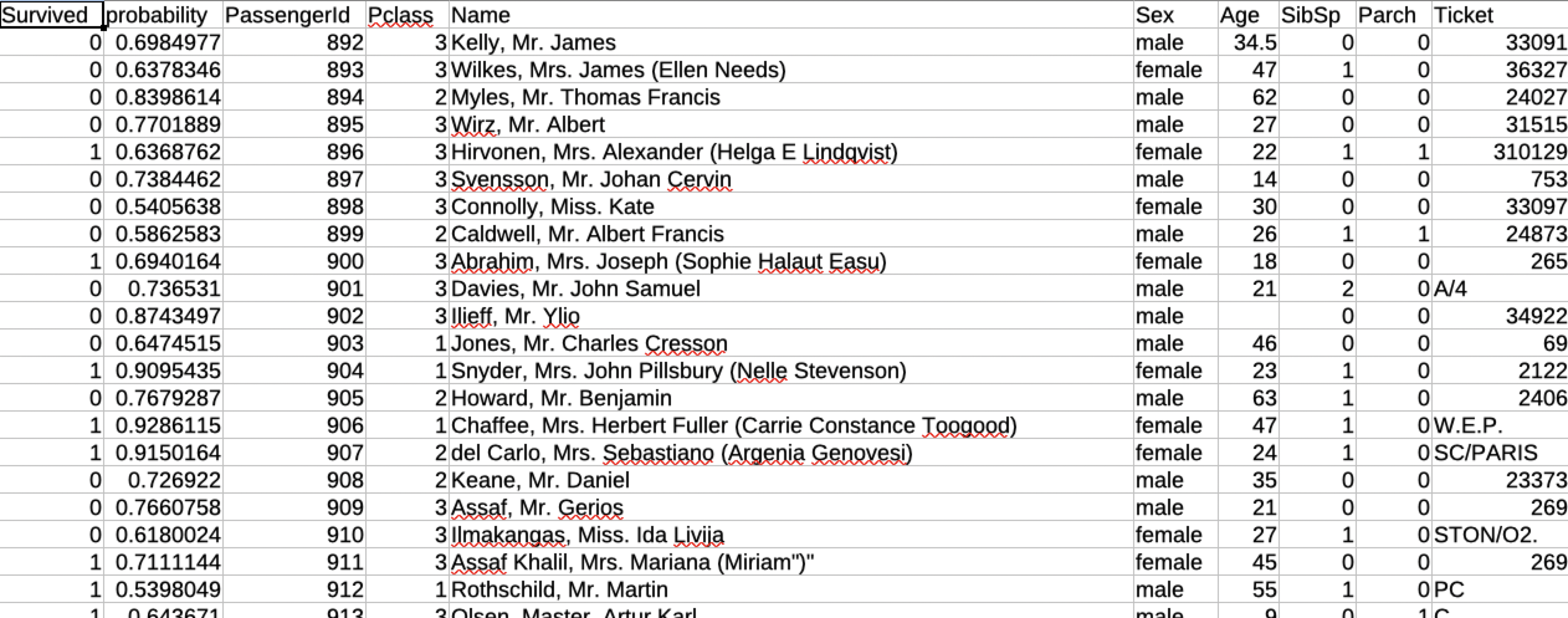
さて、予測が得られたのでこの予測がどれだけ合っているか検証しましょう。
検証するためにはKaggleのタイタニックコンペティションのページより、予測結果をアップロードします。
今回の主題と外れるのでアップロード方法については割愛します。
アップロードした結果、下記のような結果になりました。
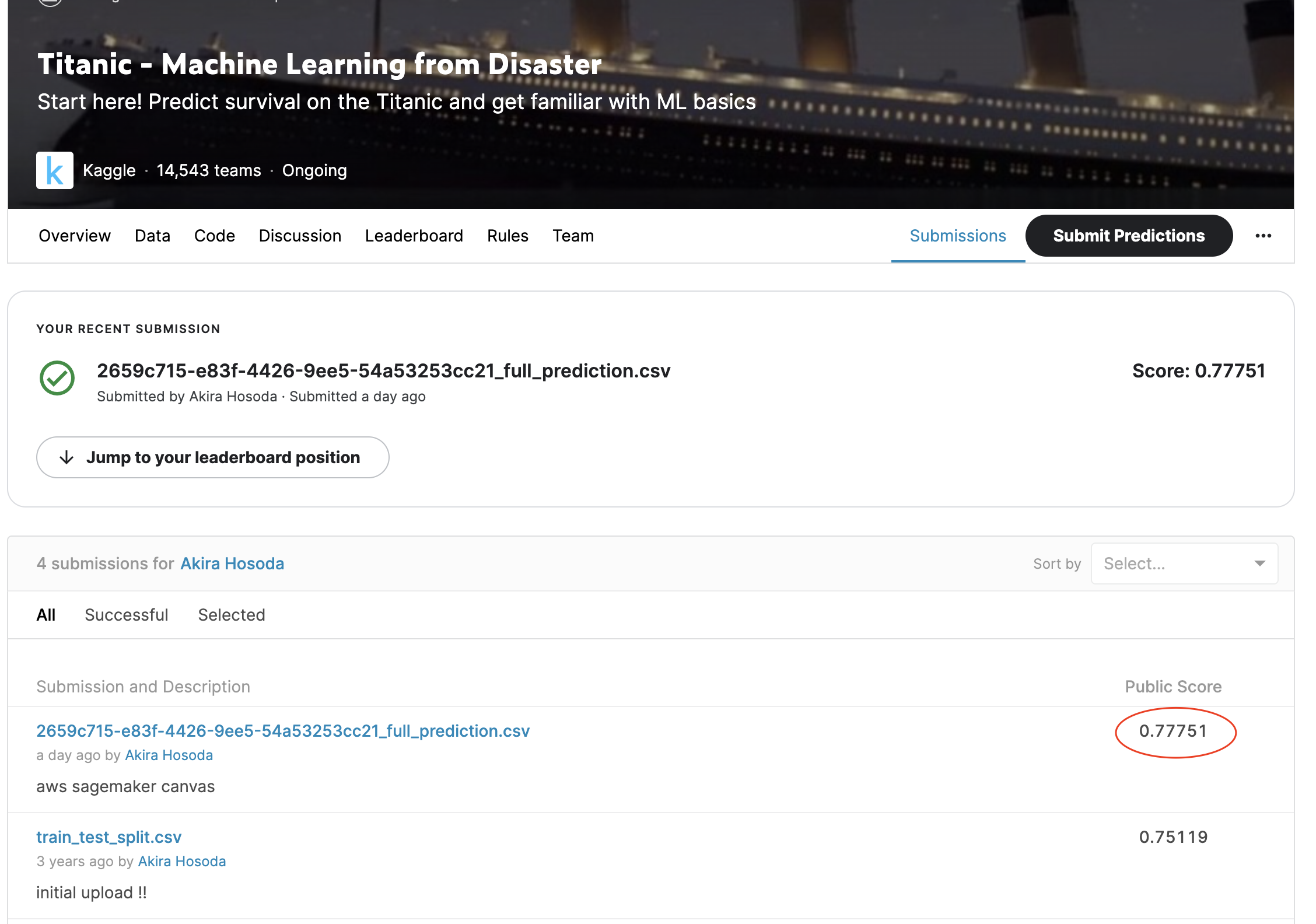
正答率は77%ですね。
以前チュートリアル通りに機械学習を進めた際の結果が75%だったので、ただ何もせずにSageMaker Canvasにデータを通すだけで、
チュートリアル以上の結果を得ることに成功してしまっています。
いい性能していますね!
これにてSageMaker Canvasの使い方・検証は完了です。
まとめ
今回はSageMaker Canvasを使用し、機械学習を行えることができました。
コードを一切描かず、グラフィカルな情報を得ることができ、予測精度が良いモデルを得ることができました。
機械学習の用途として利用せずとも、データの中で何が重要な情報なのか?などといった課題解決にも役立つと思います。
また、作業に関してもとても簡単ですので、機械学習の案件があったらとりあえず、SageMaker Canvasに投げてしまうというのもありだと思います。
色々な使い方はあると思いますが、是非ともこのサービスの触り、パワーを感じてもらいたいです。
機械学習の片鱗を触ることができ、とても刺激的な経験になるかと思います。
サーバ運用とWebサイト運用・システム運用などが業者が別々で問題解決が困難、もしくは業務をワンストップでお願いしたいなどございましたら遠慮なくご相談ください。
サーバの設計や構築のみなどミニマムな業務からも承ってますので是非コムデへご相談ください。
はじめに
みなさんは「Cloud Formation」使ったことはありますか?
後に詳しく説明致しますが、どのようなサービスか端的に説明しますと、インフラをコード化し自動的にリソースの作成を行ってくれるサービスです。
「インフラのコード化」、、モダンな響きでかっこいいですよね!
AWSの中でもぜひマスターしたいサービスですので今回はそんな「Cloud Formation」について解説してみたいと思います。
目次
1 「Cloud Formation」とは
2「テンプレート」の解説
3 作成されたリソース
4 まとめ
1「Cloud Formation」とは
「Cloud Formation」の実行の流れとしましては、
1 「テンプレート」の作成
2 「cloudformation」で「テンプレート」の適用
3 スタックが作成され、リソースが展開される
といった流れになっております。「テンプレート」さえ正しく作ることができれば、あとは「Cloud Formation」がリソースを作ってくれます。
何度も同じものを作らなくてはいけない時にミスなく実行することができるので正確に繰り返し作業をする時に便利ですし、リソース名だけ変える等使い回すこともできます。
それでは早速「テンプレート」を作っていきましょう!
2「テンプレート」の作成
「Cloud Formation」の「テンプレート」ファイルは「JSON」または「YAML」形式で記述することができます。本編では「YAML」形式で説明していきます。
#AWSTemplateFormatVersion
#cloudformationのテンプレートのバージョンです。テンプレートを書くときに必ず記述します。
AWSTemplateFormatVersion: '2010-09-09'
#Description
#テンプレートに関するコメントを書くことができます。
Description: Create VPC,Public Subnet and EC2 Instance
#parametersセクション
#parametersセクションでは実行時に値を選択する項目を定義するセクションです。以下の場合はインスタンスタイプの選択項目を定義しています。
Parameters:
InstanceType:
Type: String
Default: t3.micro
AllowedValues:
- t3.micro
- t3.small
- t3.medium
Description: Select EC2 instance type.
KeyPair:
Description:Select keypair Name.
type: AWS::EC2::Keypair::KeyName
#Mappingセクション
#Mappingセクションでは実行う環境によって変わる値を定義するのに用いられます。例えばEC2のインスタンスを作る際はAMIを選択しますがAMIのIDはリージョンによって変わります。その場合次のようにAMI IDを定義します。同じAMIでもリージョンが違うとIDが異なるので注意が必要です。
Mappings:
RegionMap:
ap-northeast-1:
hvm: '任意のAMI ID'
#Resourcesセクション
#Resourcesセクションは構築するAWSリソースの設計図のようなものです。各リソースには論理IDを付ける必要があり下記の場合だと「cfnVpc」になります。この論理IDを使ってリソース間の紐付けを行います。
Resources:
cfnvpc:
#続けてリソースの型をTypeで定義します。下記の場合は「'AWS::EC2::VPC'」の部分です。型によって「Properties」で設定できる項目が決まっています。例えばVPCの場合「CiderBlock」・「Tags」といった形です。
Type: 'AWS::EC2::VPC'
Properties:
CiderBlock: '10.0.0.0/16'
Tags:
- key: 'Name'
value: 'cfn-vpc'
cfnSunbnet:
Type: 'AWS::EC2::Subnet'
properties:
CiderBlock: '10.0.1.0/24'
MappublicIpOnLanch: true
tags:
- key: 'Name'
value: 'cfn-subnet'
#「!Ref」関数はAWSリソースの値や設定されたパラメータの値を取得する関数です。「parameters」セクションで定義された値を「!Ref」関数を用いて参照します。
VpcId: !Ref cfnVpc
cfnInternetGateway:
Type: AWS::EC2::InternetGateway
Properties:
Tags:
- key: 'Name'
Value: 'cfn-igw'
cfnEC2Instance:
Type: 'AWS::EC2::Instance'
Properties:
#Mappingsセクションの値をfindInMap関数で取得
InstanceType: !Ref InstanceType
SubnetId: !Ref cfnSubnet
BlockDeviceMappings:
- DeviceName : '/dev/xvda'
Ebs:
VolumeType: 'gp2'
volumeSize: 8
Tags:
- key: 'Name'
- Value: 'cfn-ec2-instance'
SecurityGroupIds:
- !Ref cfnSecurityGroup
KeyName: !Ref keyPair
3 作成されたリソース

上記のようになります。こちらにルートテーブルやロードバランサー、Route53の設定をすれば最低限環境構築は完了です。
上記以外にも、キーペアの設定・Nameタグの設定・インスタンスタイプの選択機能・EBSストレージの設定ができている形になります。
4 まとめ
いかがでしたでしょうか?「Cloud Formation」はインデントがかなり厳しく半角1つずれてもすぐエラーになってしまうので作ることが難しいですが一度作ってしまえばそれ以降作業はかなり楽になると思います。AWSのリソースがミスなく構築できるので業務の効率化につながること間違いなしです。是非使ってみてください!
はじめに
AWSには「Cloud9」というサービスがあります。
このサービスはクラウドIDEと呼ばれるもので、サーバーのファイル操作やコンソール操作をIDEで操作することができます。
Cloud9はEC2インスタンスを使用しているため、下記のメリットがあります。
- サーバー上でIDEを使用しているかのようにコード開発をすることができる
- コード開発をしなくとも、ちょっとしたenv修正なんて使い方もGoodです
- 使っているパソコンのスペックが悪くても処理が重いプログラムを動かせる
- ネット環境さえ整っていれば、ハイスペマシンの操作をどこでもできます!
- 他の人にも環境を共有することができる
- 同じインスタンスを見ることになるので。コンフリクトには要注意です
- 自分のローカル環境を汚さなくて済む
- スクラップ&ビルドが容易なクラウド環境でこの親和性は大変高いです!
個人的に最初触った時の衝撃が大きく、AWSサービスの中で一番好きなサービスだったりします。
さて、話は変わりますが、AWSには無料枠というものが存在します。
これはt2.microなどのインスタンスを1台分、無料で運用できるというものです。
ただし、アカウント作成から1年間の期間限定です。
GCPではus-***-1リージョンのe2-micro 系が永久に無料という魅力的な無料枠があります。
個人でちょっとしたサービスを作るときやサーバーで遊ぶ分にはこの枠が大変魅力的ですね。
ただ、GCPにはCloud9のようなクラウドIDEは存在しません。
コンソールくらいは動かすことができるのですが、vimmerなどの特殊な人以外、コード開発をするのには向いていません。
今回はそんなGCPにクラウドIDEを導入する方法を紹介します。
目次
- GCPの無料枠
- 環境作成手順
- まとめ
GCPの無料枠
今回のインスタンス設定はGCPの無料枠を使うということを考慮し、下記で設定しています。
us-west1は日本に一番近いリージョンなので選択していますね。
リージョン:us-west1(オレゴン)
ゾーン:us-west1-a
マシン構成:e2-micro
ブートディスクの種類:標準永続ディスク 30GB
参考資料:https://cloud.google.com/free/docs/gcp-free-tier/#compute
環境作成手順
まず、GCPアカウントを作っていない方はGCPアカウント・請求先アカウントの作成から初めてください。
また、請求アラート設定を行なっていない方は設定した方が安心かと思います。
今回はアカウト作成を行なった後を前提としてスタートします。
1.新規プロジェクト作成
GCPログイン後、左上の①プロジェクト→②新しいプロジェクトを選択する。
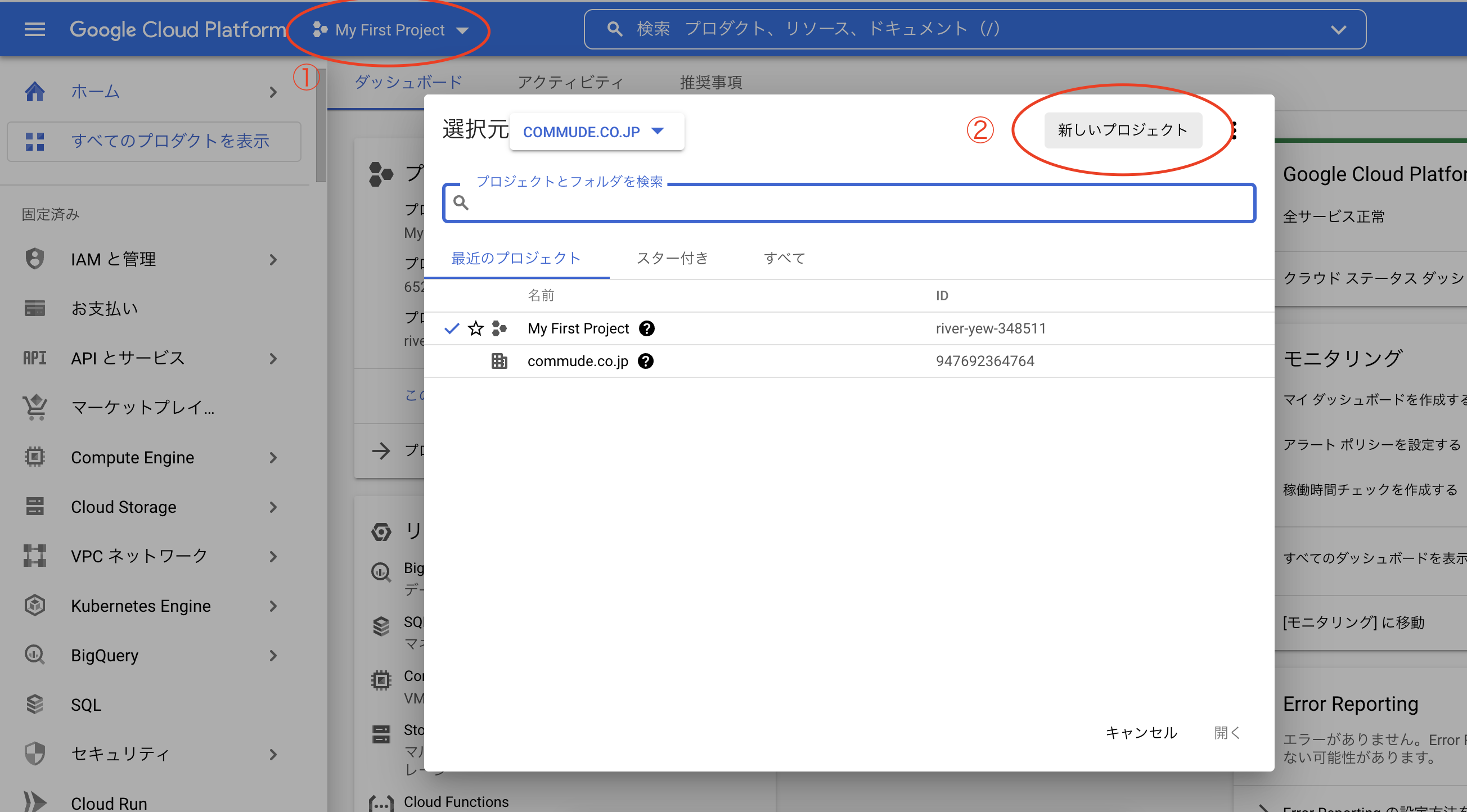
任意のプロジェクト名を設定し、プロジェクトを作成します。
GCPではプロジェクト単位でインフラを管理していきます。
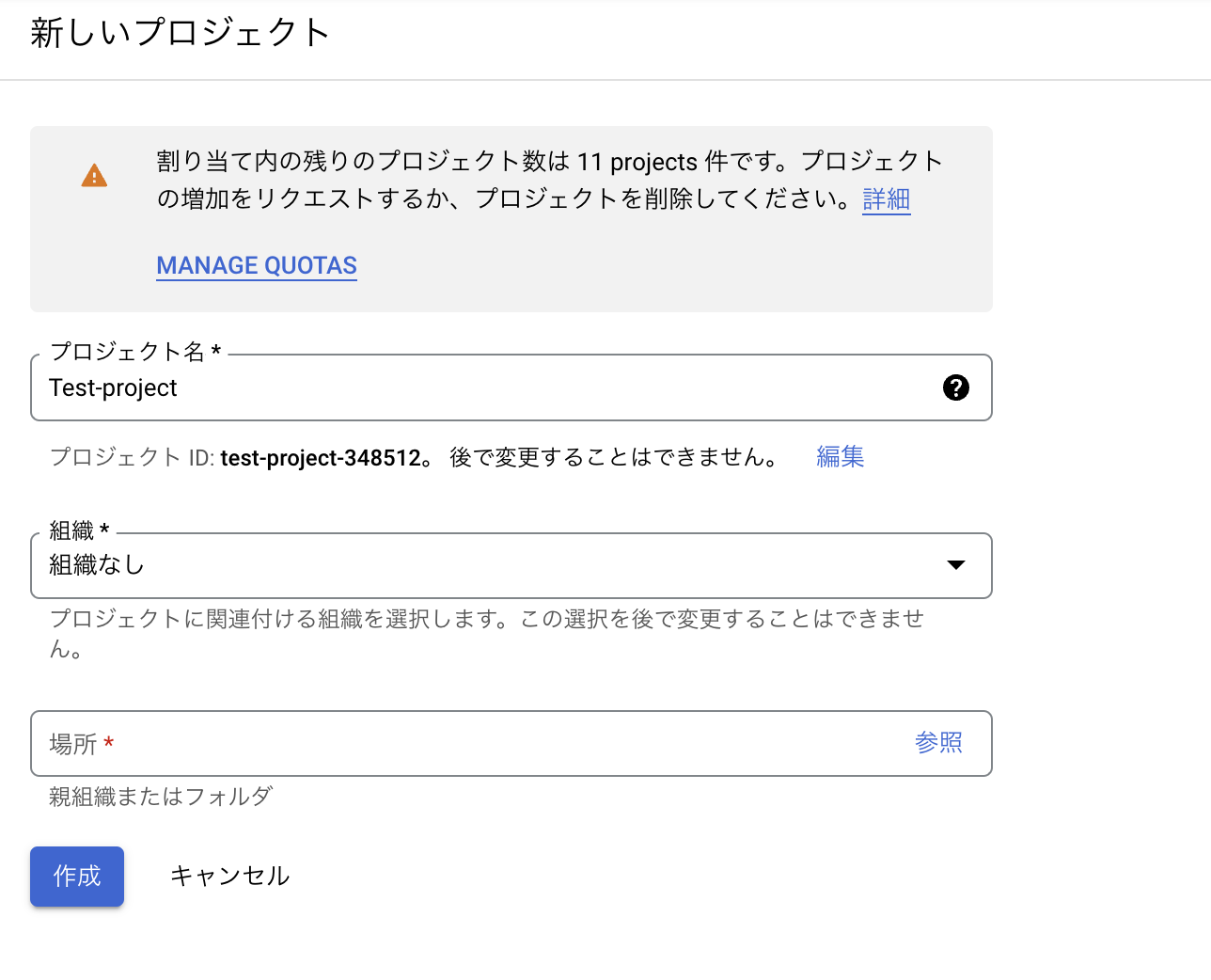
プロジェクトの作成が終わったら、コンソール左上から先ほど作成したプロジェクトを選択します。
2.VMマシン作成
左のメニューよりVMインスタンスを選択します。
表示された画面より「インスタンス作成」をクリックし、インスタンス作成画面に移ります。
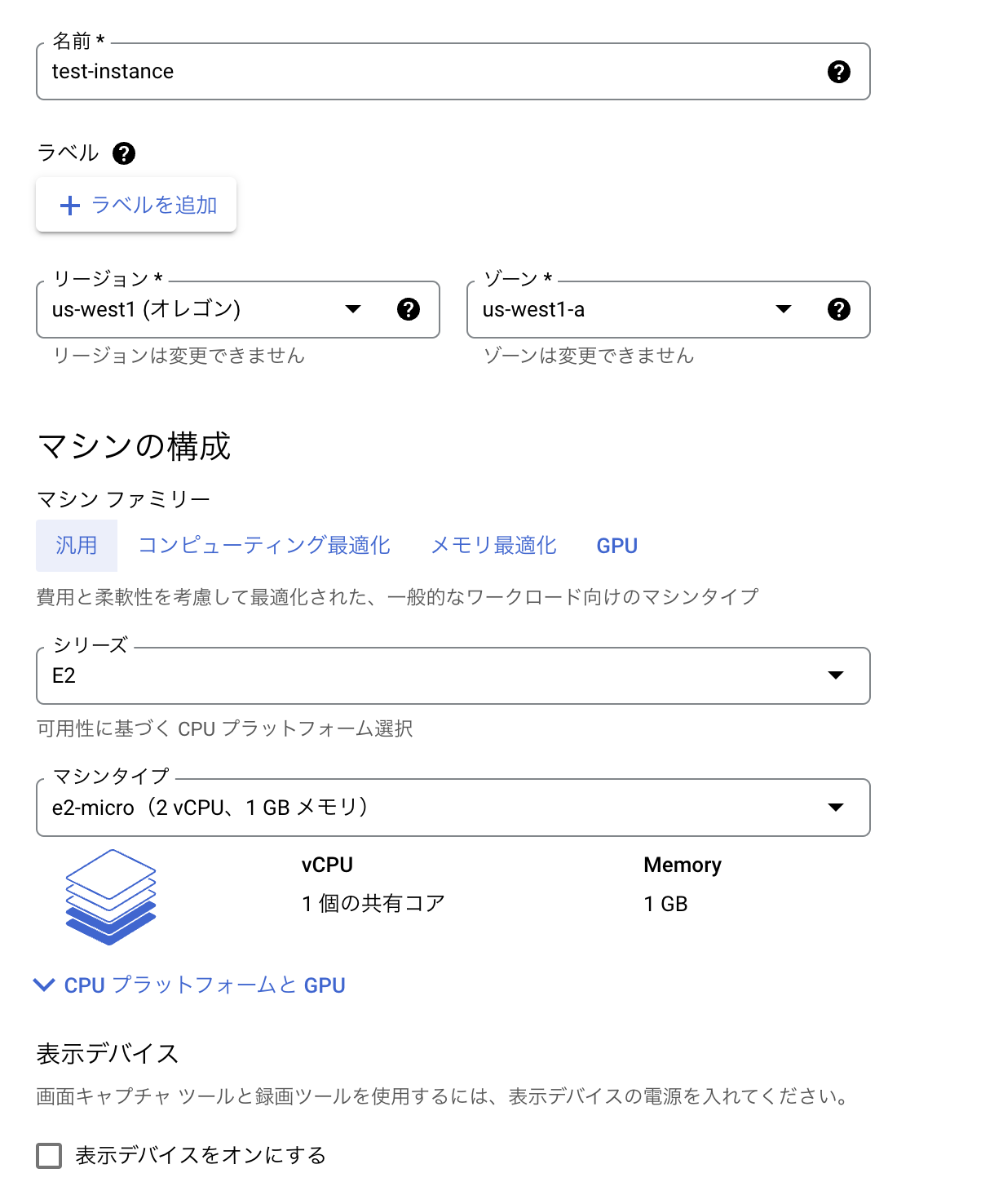
リージョンやマシン構成などは下記のとおり、無料枠で収まるよう、設定します。
OSは好きなもので大丈夫です。
今回はデフォルトのDebianを使用します。
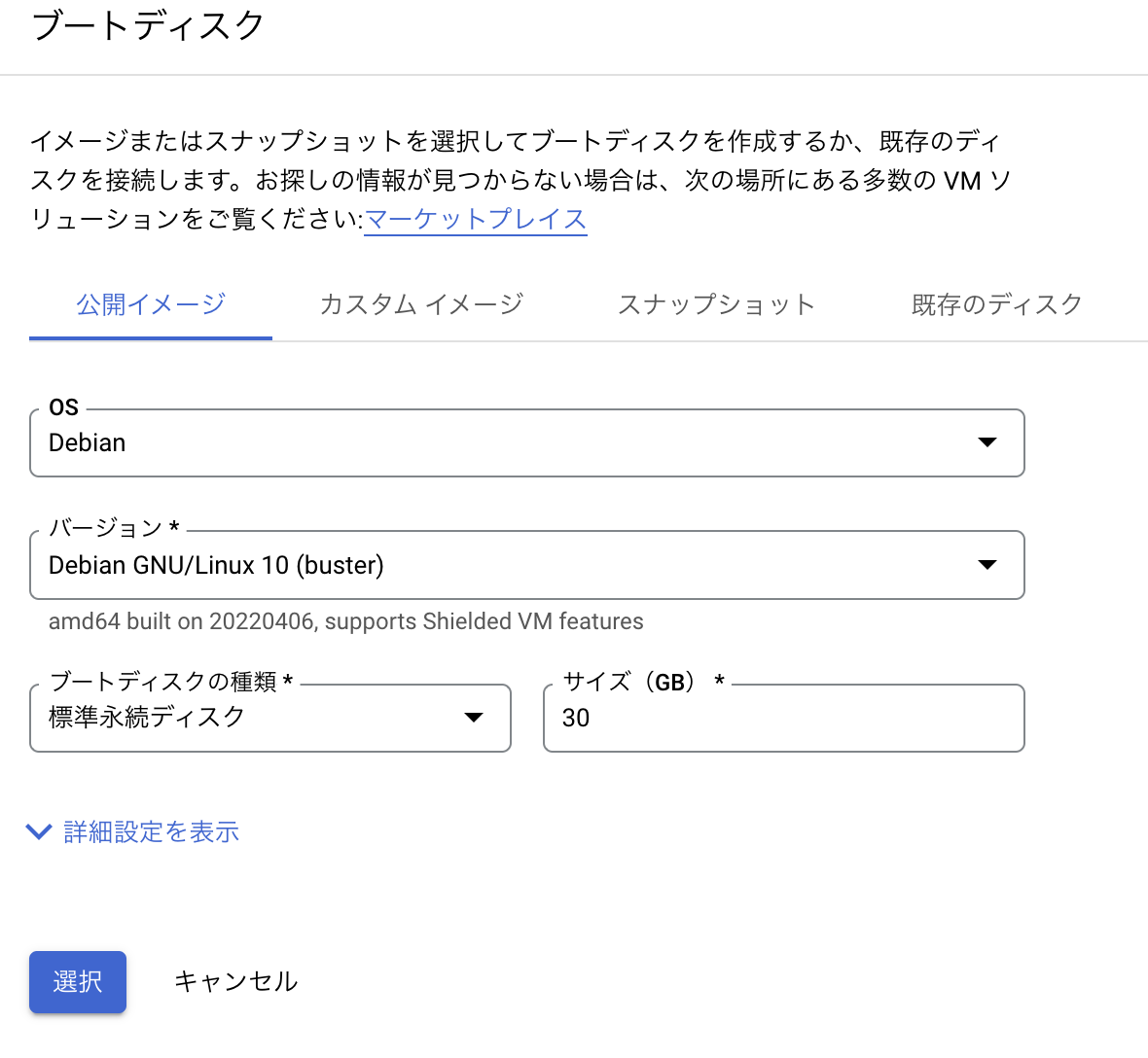
ブートディスクは30GBまで無料で使用できるのでデフォルトから変更します。
今回はチェックを入れていませんが、ブログなど公開される方は「HTTPトラフィックを許可する」もしくは「HTTPSトラフィックを許可する」にチェックを入れてください。
セキュリティ設定は各々願いします。
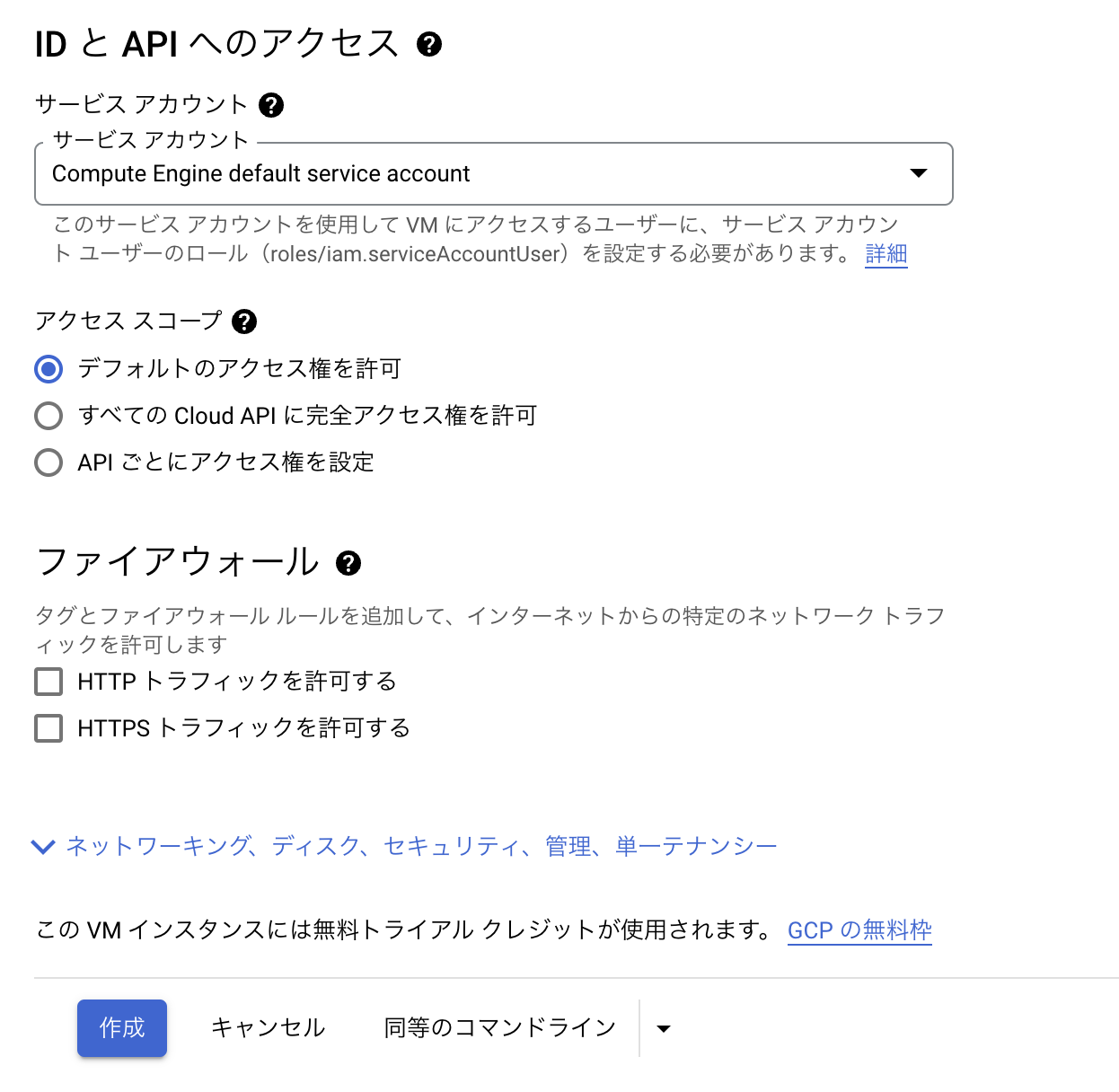
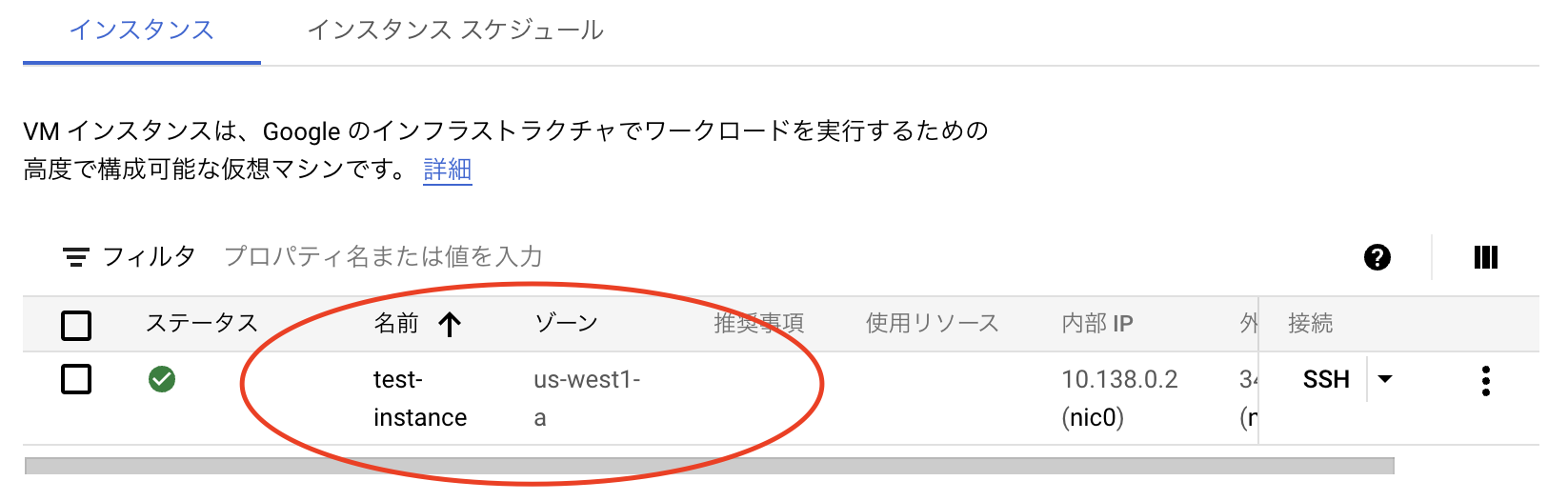
最後に「作成」をクリックし、少し待つとインスタンスが作成されます。
3.静的外部IPアドレスの
このままですとインスタンス停止のたび、IPアドレスが変わってしまうので静的なIPアドレスをインスタンスに設定します。
先ほど作成したインスタンスを選択し、画面上部の「編集」をクリックすると編集画面に遷移できます。
項目「ネットワークインターフェース」より「外部IPv4アドレス」を選択し、「IPアドレスを作成」をクリックします。
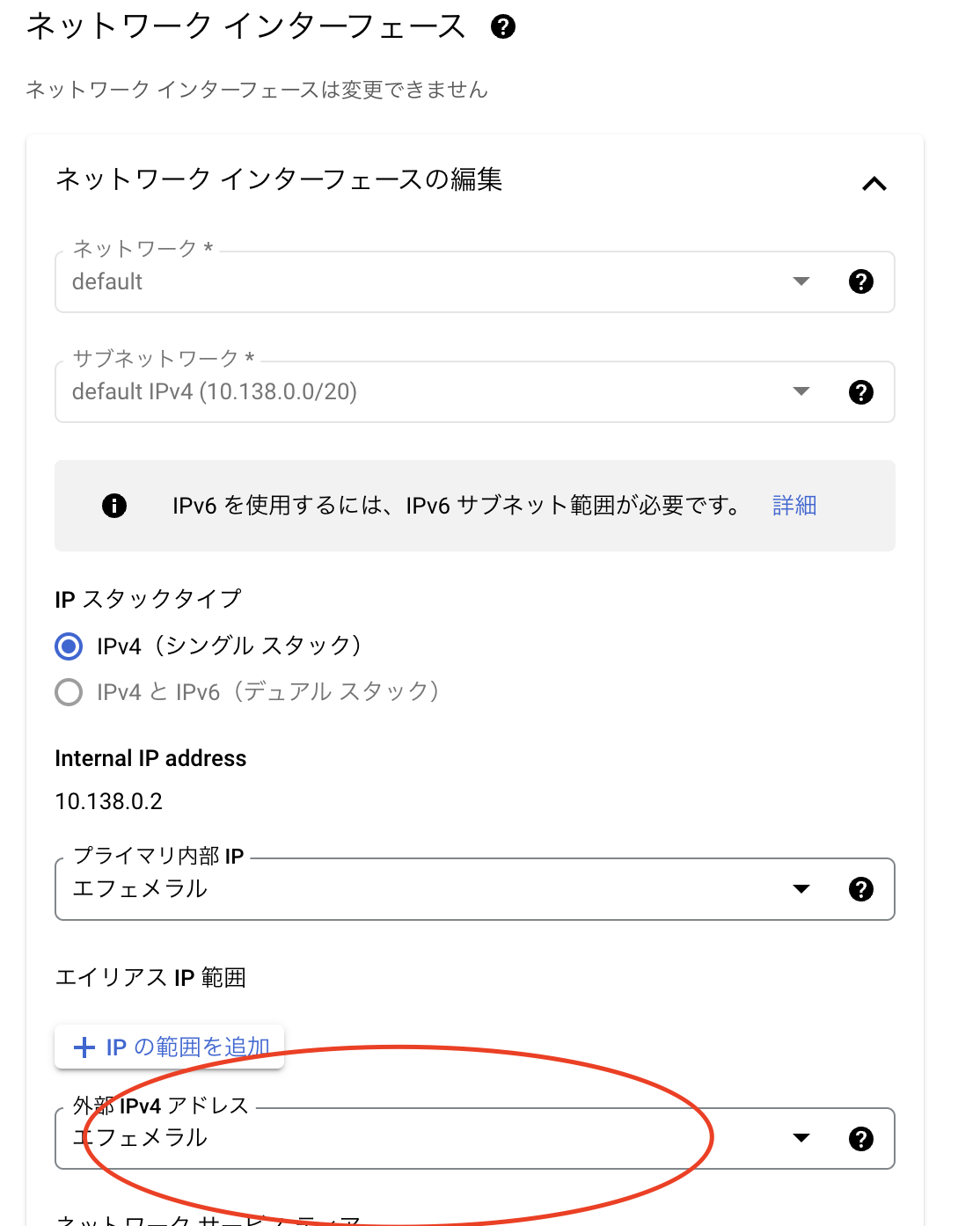
表示されたモーダルにて任意の名前を入力し、「予約」をクリックします。
最後にインスタンスの設定内容を画面左下の「保存」をクリックし、保存します。
インスタンス詳細画面にて静的IPが設定されていることが確認できますね。
これで静的IPの設定は完了です。

静的IPはインスタンスに割り当てていないと割高な料金を請求されているため、使用しなかった場合は必ず解放してください。
4.SSH通信環境の作成
次にインスタンスとSSH通信をできる環境を作成していきます。
ローカル環境のコンソールから下記コマンドなどで秘密鍵と公開鍵を作成してください。
ssh-keygen -t rsa生成された公開鍵を下記コマンドなどで確認します。
cat id_rsa.pubそれでは、公開鍵をインスタンスに設定していきます。
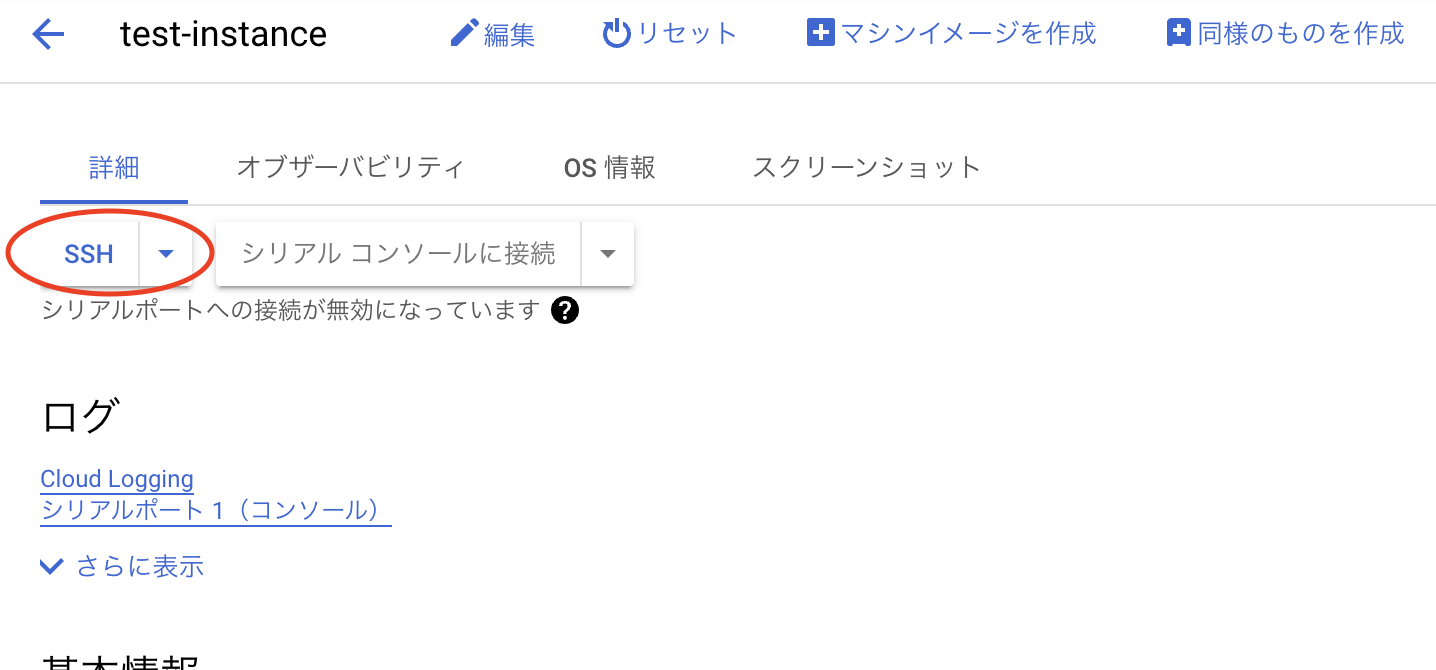
インスタンス詳細の上部にある「SSH」をクリックしてください。
別タブにてインスタンスのコンソール画面が表示されます。
コンソールにて下記コマンドを実行し、インスタンスに対して公開鍵を設定していきます。
cd .ssh
vim authorized_keysインスタンスに公開鍵を設定し終えたらローカルのコンソール上から下記コマンドでssh通信ができるか試してみてください
ssh {googleのアカウント名(.は_に置き換わる)}@{静的IPアドレス} -i ~/.ssh/id_rsa無事、疎通確認が取れたかと思います。
次はローカル上で下記コマンドを実行し、configを編集します。
cd ~/.ssh
vim config設定内容は下記になります。
Host gcp
HostName {静的IP}
IdentityFile ~/.ssh/id_rsa
User {googleのアカウント名(.は_に置き換わる)}
ServerAliveInterval 60
TCPKeepAlive yesあとは下記コマンドを実行し、疎通確認を行います。
無事、インスタンスに入れたらsshの設定は完了です
ssh gcp5.VSCodeの設定
今回はローカルのエディタとしてVS Codeを使用していきます。
インストールされていない方は下記からインストールしてください。
https://code.visualstudio.com/
ここでは、VS CodeでのSSH接続設定をしていきます。
左のメニューから①拡張機能を選択し、②検索フォームに「ms-vscode-remote.vscode-remote-extensionpack」で検索します。
表示された拡張機能「Remote Development」を③インストールします。
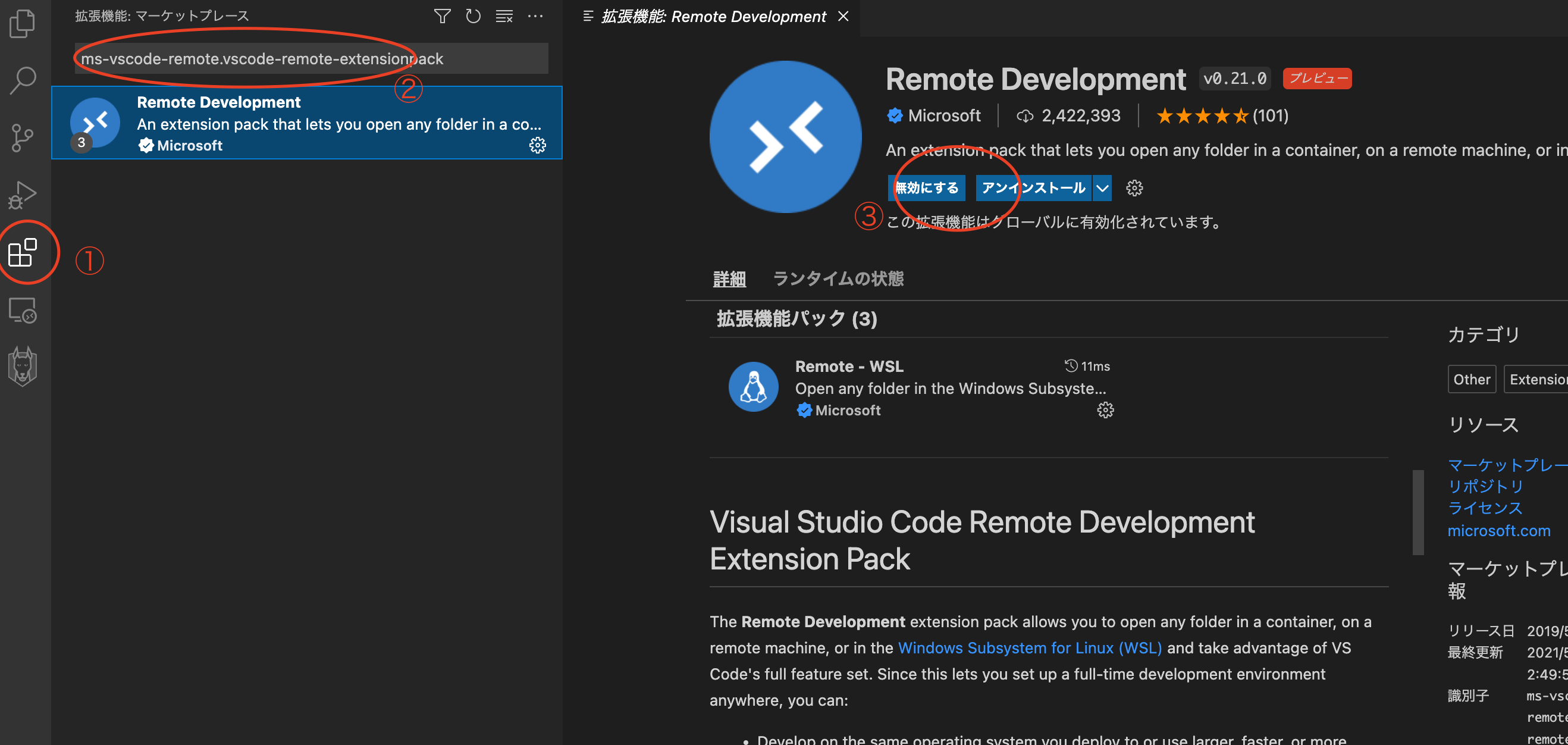
無事、インストールできたら、左メニューにリモートエクスプローラが表示されます。
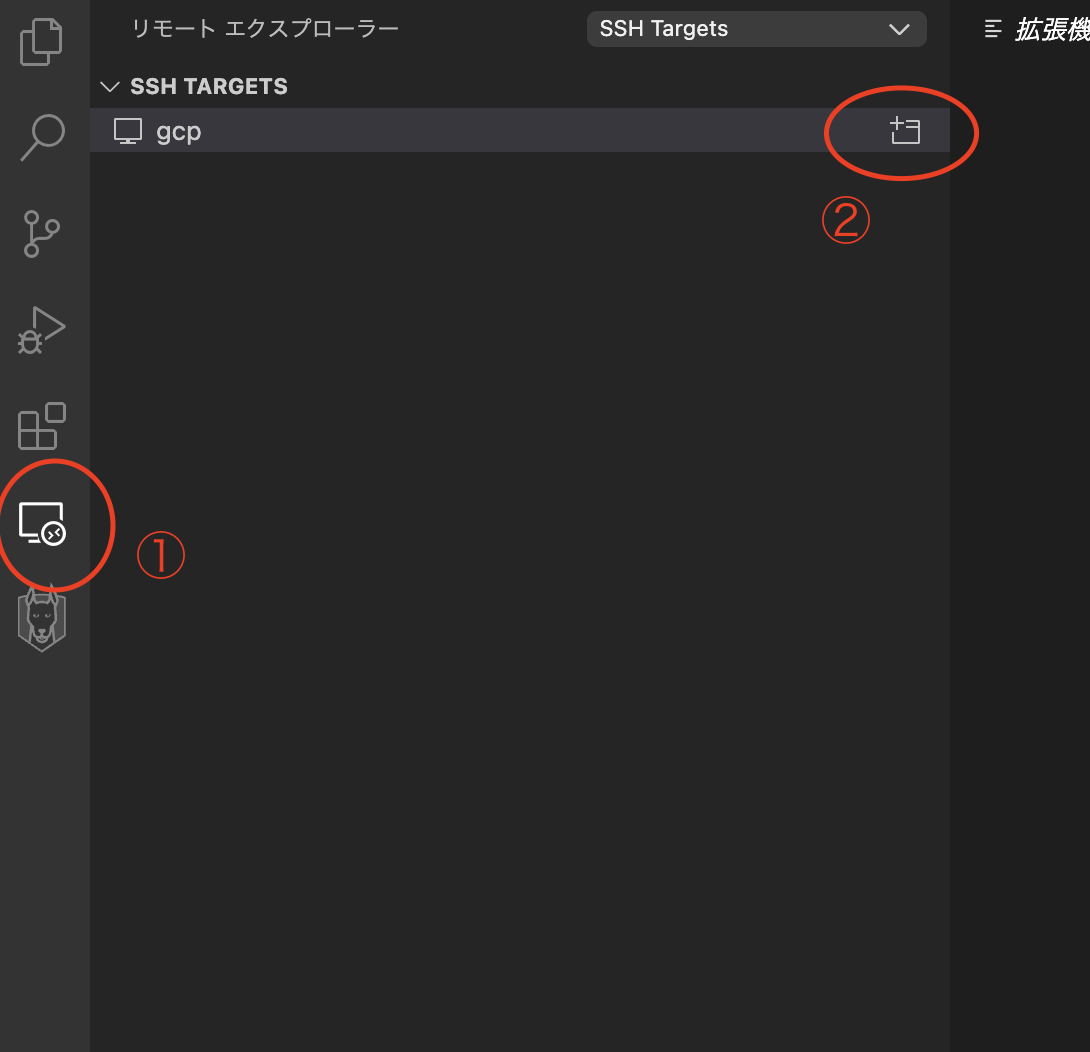
①リモートエクスプローラをクリックすると、sshのconfig内容が一覧で表示されます。
先ほど設定したconfigの右にある②ボタンをクリックすると、新規 VSCodeが立ち上がります。
新規VSCodeでは画面左下にSSH通信の接続先が表示されているはずです。
これでVSCodeとインスタンスの紐付けは完了です!
ファイルを直接操作する際は「①エクスプローラー」→「②フォルダーを開く」で
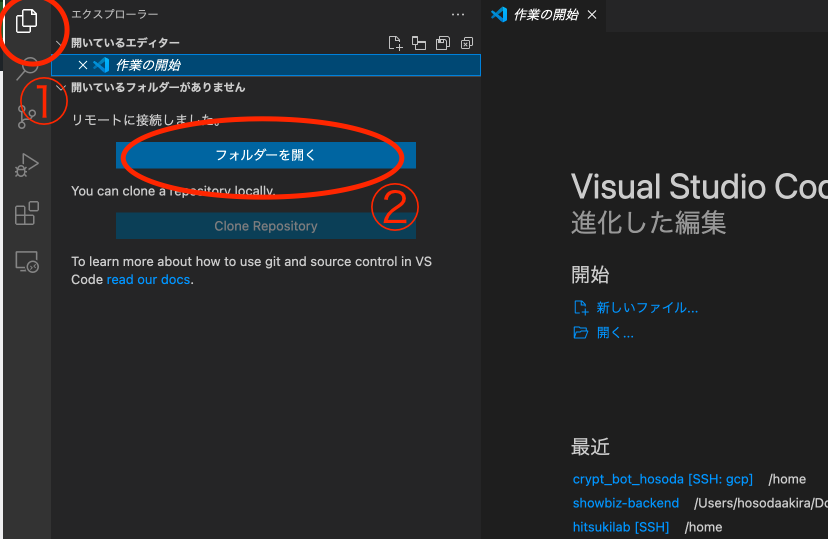
下記のようにサーバー内のフォルダへアクセスすることができます。
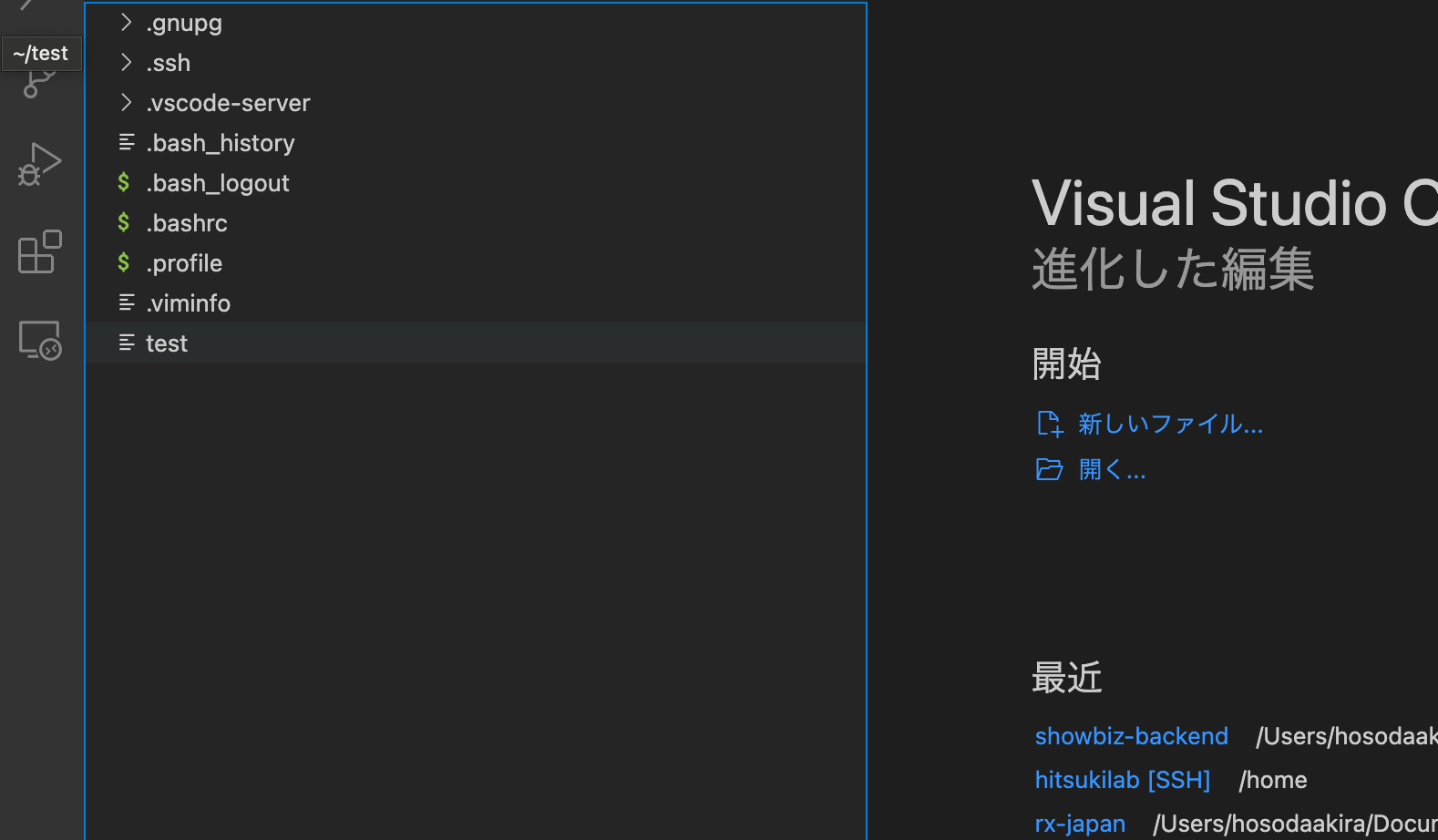
あとはローカル環境で使用している感覚でサーバー内のソースコードを書き換えることができます。
ターミナルを開きたい場合は「ターミナル」→「新しいターミナル」で開くことができます。
ターミナルを開き、ソースコードを実行することも可能です。
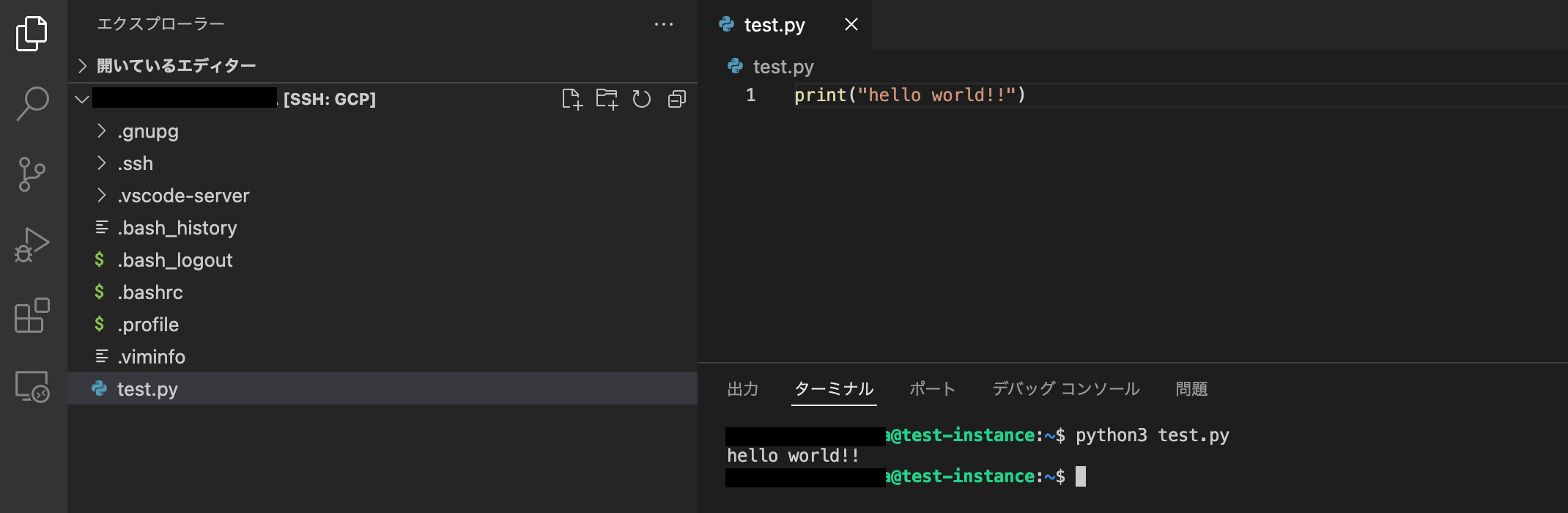
以上でGCPでCloud9ライクな環境の作成は終了です!
まとめ
今回はGCP環境でCloud9のような環境を作成することができました。
この環境はGCPに限らず、どの環境でも作成することができます。
ぜひ、ご自身で試してみてください。
また、現在Cloud9を使用している場合でもCloud9よりもVSCodeを使った環境の方が
- いちいちコンソールにアクセスしなくて良い
- VSCodeの拡張機能を使用することができる
といった面で、メリットが得られます。
これを機に環境を切り替えるのも良いと思います。
しかし、Cloud9にも下記のようなメリットがありますので用途に合わせて考えてみてください。
- 使用する時のみインスタンスを立ち上げる設定ができるのでインフラコストが安い
- 初期設定が1分程度でできてしまう
サーバ運用とWebサイト運用・システム運用などが業者が別々で問題解決が困難、もしくは業務をワンストップでお願いしたいなどございましたら遠慮なくご相談ください。
サーバの設計や構築のみなどミニマムな業務からも承ってますので是非コムデへご相談ください。
はじめに
コンテナって便利ですよね!ECSはexecが使えるようにアップデートされてからコンテナを利用する人も増えたのではないでしょうか?コンテナやサーバレス関連のアップデートは凄まじく、最近はEC2を使う機会がかなり減ってきましたね。今回はECS exec
execエラー確認
最近こんなエラーがでました。
An error occurred (TargetNotConnectedException) when calling the ExecuteCommand operation: The execute command failed due to an internal error. Try again later.execのエラーが起きた場合は最初に下記の設定ができているか確認してみてください。
・Amazon ECS タスクロールに execute-command コマンドを実行するために必要なアクセス権限がない
・コマンドを実行しているIAMロールまたはユーザーに、必要なアクセス権限がない
・AWS CLIがインストールされている
・Fargateのプラットフォームバージョン「1.4.0」以降を利用している
・「Session Managerプラグイン」をインストールしている
上記の設定すべてを対応してもエラーが解決しない場合も残念ながらあります。。その時は amazon-ecs-exec-checker スクリプトを実行してみてください。 amazon-ecs-exec-checker を使えばAWS CLI 環境および Amazon ECS クラスターまたはタスクを確認、検証できます。このスクリプトは、満たされていない前提条件 についても通知してくれます。
amazon-ecs-exec-checker スクリプト
README.md 記載通りにやれば簡単に利用できます!
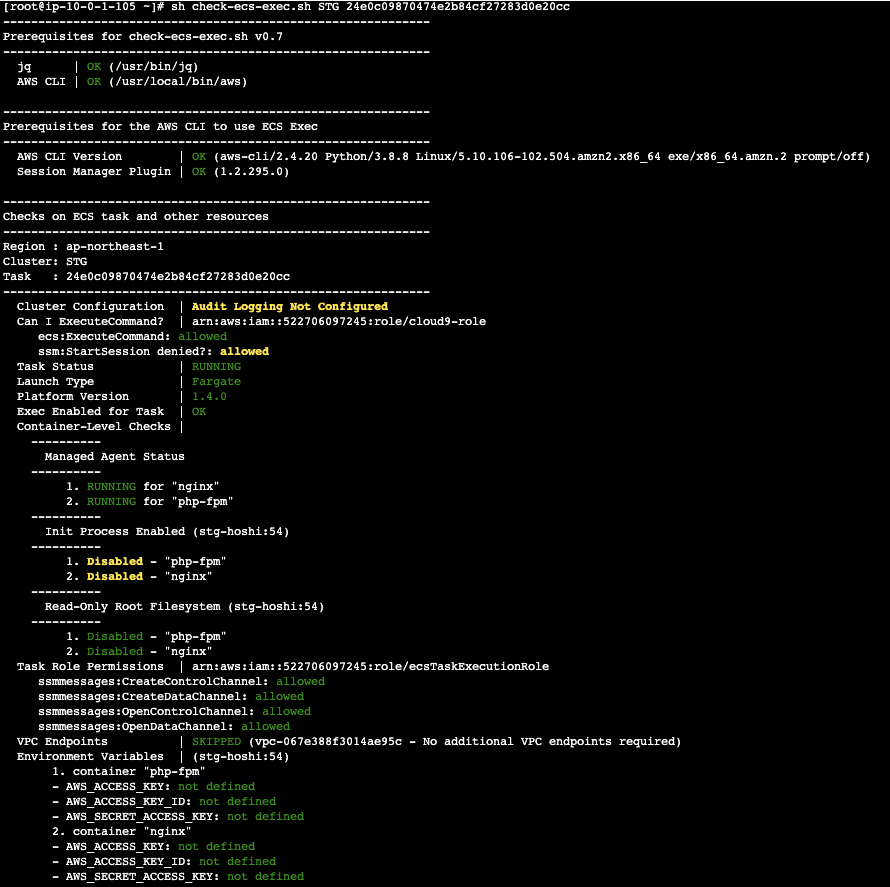
今回はnginxとphp-fpmのコンテナを用意して試して見ましたが問題なさそうですね!しかし、それでも最初のエラーが解決しませんでした。。。
結論
原因はタスク定義の環境変数の中に下記値が入っていたからでした。
AWS_ACCESS_KEY
AWS_SECRET_ACCESS_KEY
amazon-ecs-exec-checker スクリプトでも引っかからないので大変でした。。
アプリケーションへの権限付与はIAMユーザーを作成するのではなくタスクロールで権限を付与しましょう!!
参考
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ecs-error-execute-command/
はじめに
昔はお金が潤沢になければ1台のサーバーにサイトをいくつもいれてデータベースは勿論共用、どちらもカリカリにチューニングをして使っていました。
バックアップはテープにとっていたとしても、リカバリの予行練習なんてしてないことも・・・。
サーバーセンターで回線借りると1Mbpsあたり五万円くらいしてた様な気がします。
時代が進みAWSなどのクラウドサービスがでてきてお金が無くてもサーバーを複数台使って冗長化できるようになるとアプリケーションの更新は複数台のサーバーにSSHでログインして同じ事しないといけなくなりました。
tmuxつかって同時作業してみたり、chef使って頑張ってみたりです。そういえばAWSでchefを使うサービスもありました。
そして、最近インフラを触っていて感じるのはSSHを使う事が減ってきたなってことです。
その理由はいくつかあります。一番大きな理由はやはりコンテナを使うようになった事です。また、LambdaやAppSyncなどのサーバーレスのサービスを商用でそれなりに使うようになって来ました。
今回kubernetesよりはわかりやすいけれどそれなりに理解するのが大変な AWS ECS の概念について解説したいと思います。
目次
- ECSってなんだろう?
- ECSの構成
- まとめ
ECSってなんだろう?
まず、前提としてEC2を使ったECSについては考えないです。
ECSはコンテナを管理する仕組みです。たとえば自分でサーバーを立ててコンテナを起動してサービスを始めたとします。
コードを修正したときにやらないと行けない事はこの様な感じだと思います。
- 更新したプログラムをDockerイメージにコピーする。
- そのイメージをDocker HubやAWS ECRにpushする。
と、ここまではCIを入れていればやってくれますし、手作業でも1回行うだけです。その後
- コンテナを起動しているサーバーにSSHログインして新しいDockerイメージをpullする。
- 古いコンテナを停めて新しいコンテナを作成する。
サーバーが3台あれば3回これを行います。負荷がかかってサーバーを増やす場合、AutoScalingして起動時にコンテナが立ちあがるようにしておけば良いのですがその設定も一苦労です。また、EC2インスタンスは起動するのに数分かかります。
それをECSを使えば100個コンテナがあっても一気に更新できるし、負荷がかかれば数字を変えてボタンを押すだけで必要なだけコンテナを増やすことが出来ます。
ECSの構成
基本は以下の3つで構成されています。
- タスク
- これで一つのアプリケーションみたいな感じ
- コンテナの集合
- 例えばPHPを動かすならnginxとphp-fpmのコンテナを連携させて動かすように設定する。
- タスク定義として設定する
- タスク定義 ≒ docker-compose.yml
- サービス
- タスクを決めた数動かし続けてくれます。
- 他にも例えばどのロードバランサ使うのかとか、タスクをデプロイするときは1台ずつとか全部まとめてとか色々。
- サービスで動かせるタスクの種類は一つ。
- クラスタ
- サービスとタスクのカタマリ
- 一番大きな集合
箱入りの饅頭とか大福を想像するとちょっと分かりやすいかもです?
そして、饅頭の種類が色々あっても構わないわけです。茶色い饅頭はPHPのサービス、白い饅頭はnodeのサービスみたいに。
- タスク ➡️ あんこ
- サービス ➡️ 皮
- クラスタ ➡️ 箱

ECSはこれらをAWSのコンソールから簡単に管理出来るサービスです。
ただし、ELBやVPCなど他のサービスのことを理解してつかう必要があります。
まとめ
上記はECSのFargateでの運用について書きました。Fargateは出た当初高かったのですが今は価格もこなれてきてEC2インスタンスより細かく制御しやすいのとFargateスポットが激安なので上手く使えばコストも抑えられます。
AWSを使う理由の1つは管理を楽にするためなので使えるサービスはどんどん使っていきたいです。
サーバ運用とWebサイト運用・システム運用などが業者が別々で問題解決が困難、もしくは業務をワンストップでお願いしたいなどございましたら遠慮なくご相談ください。
サーバの設計や構築のみなどミニマムな業務からも承ってますので是非コムデへご相談ください。
はじめに
今回はGUIでシステムを構築できる楽しげなAWSサービス「AWS Step Functions」を使ってみました。その使用感などをお伝えできればと思います。
目次
- AWS Step Functionsとは
- 実際に試してみた
- 料金体系
- まとめ
AWS Step Functionsとは
Step FunctionsはGUIでワークフローを定義することで簡単にシステム作成することができるAWSサービスです。プログラムやインフラを用意せず、システムを作れてしまうので、ちょっとした問題であれば爆速で解決することができてしまいます!
また、AWSサービスを直接呼び出すことができるので、他のサービスへの統合がとても簡単なところも良いところですね。
今回はそんなStep Functionsを試しに使ってみました。
参考:AWS Step Functions とは
実際に試してみた
今回はStep Functionsで解決したい課題を「定時になったらインスタンスを停止する」に設定しました。Step Functionsではステートマシン単位で実行していきます。
ステートマシンはワークフローとIAMロールなどの設定がまとまったものと考えてください。
Step Functionsのステートマシンの起動にはEventBridgeを使用し、毎日20時にステートマシンを起動するようにします。
-
新規ステートマシンの作成
AWS Step Functionsを開き、「ステートマシン」> 「ステートマシンの作成」を選択します。
今回はデフォルト設定で進んでいきます。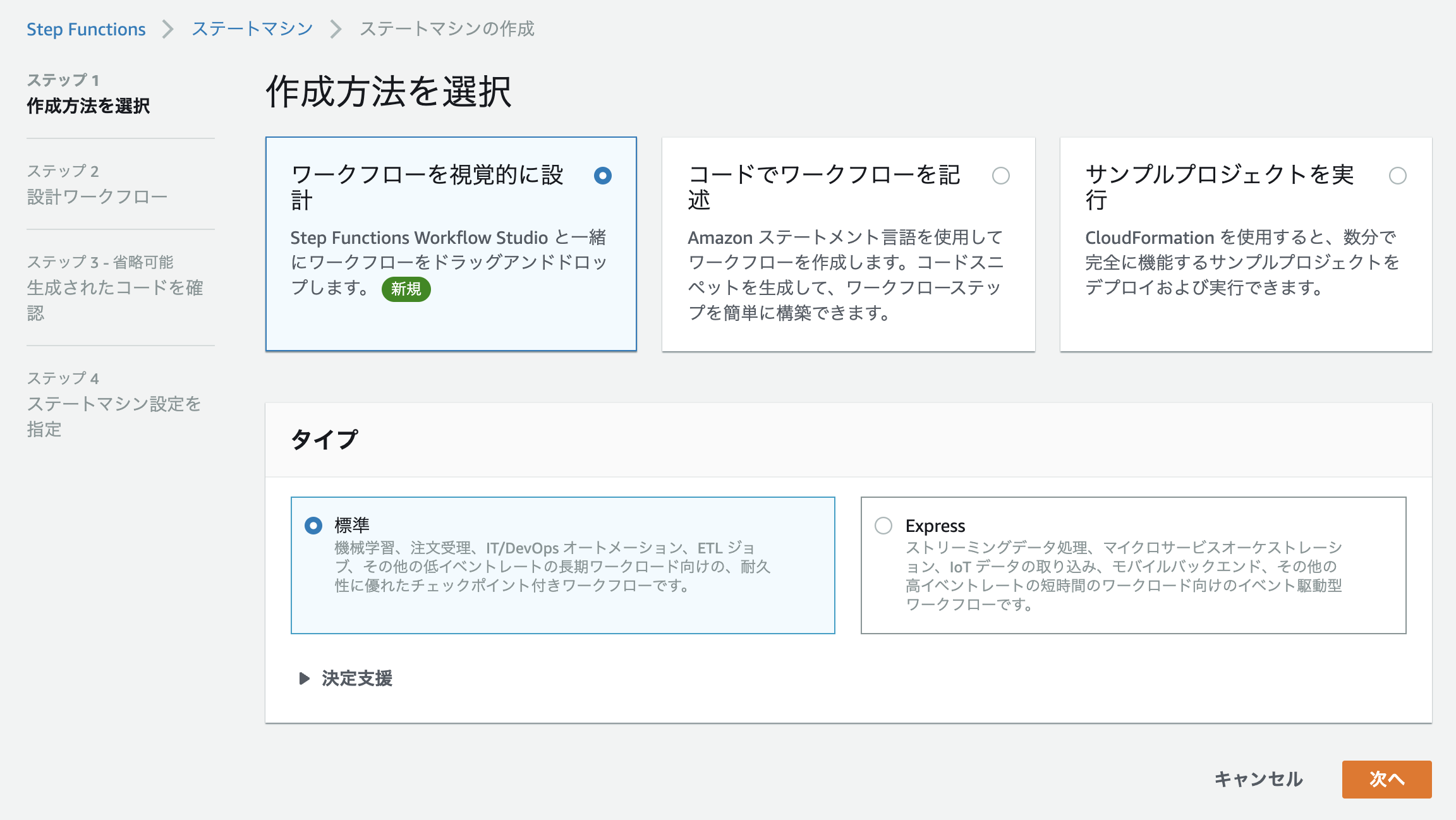
-
ワークフローの作成
- Step Functionsではこのワークフローをキャンバスに、視覚的に操作するだけで簡単にシステム構築することができます。
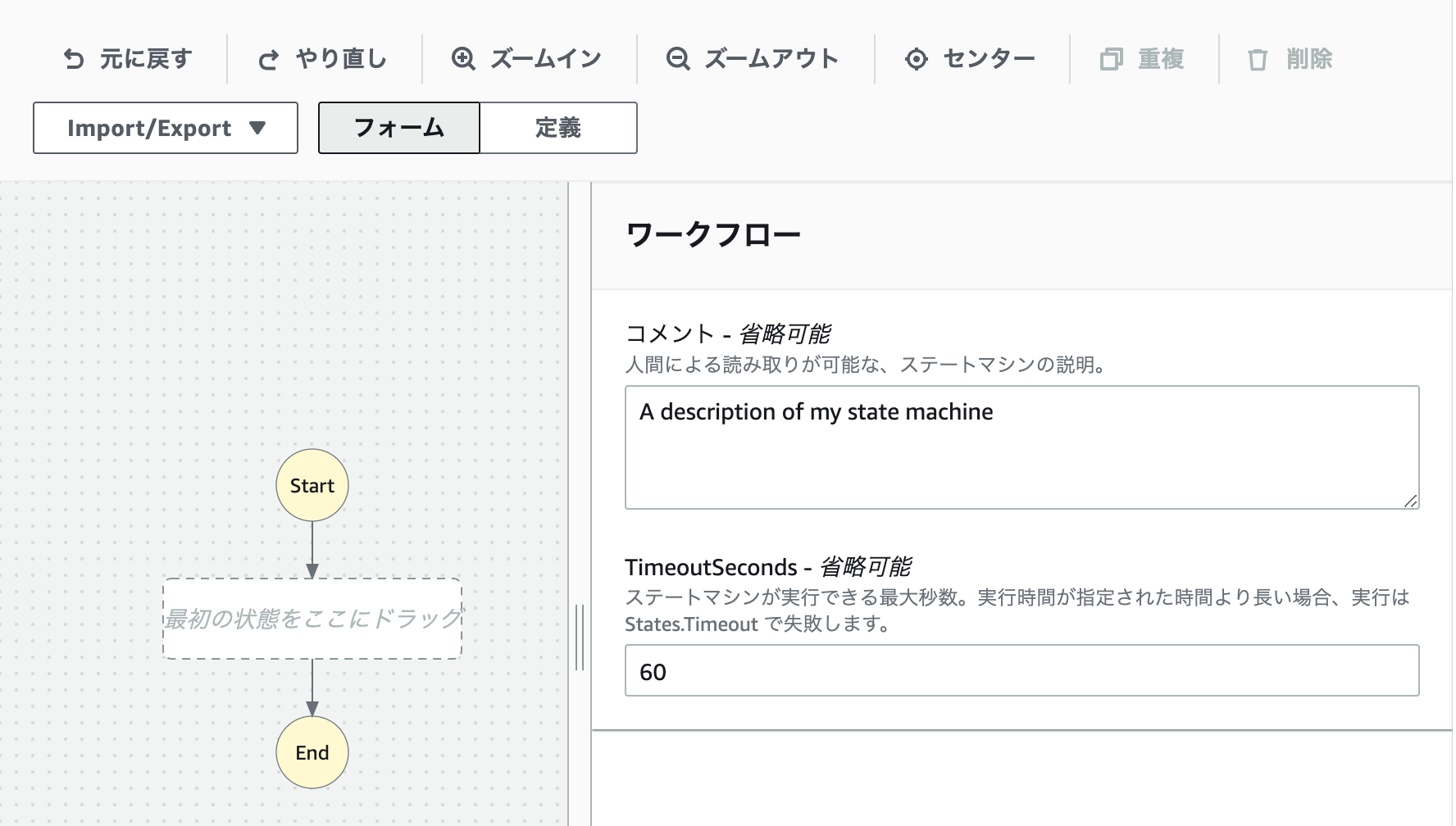
まず初めにワークフローのタイムアウトを設定しましょう。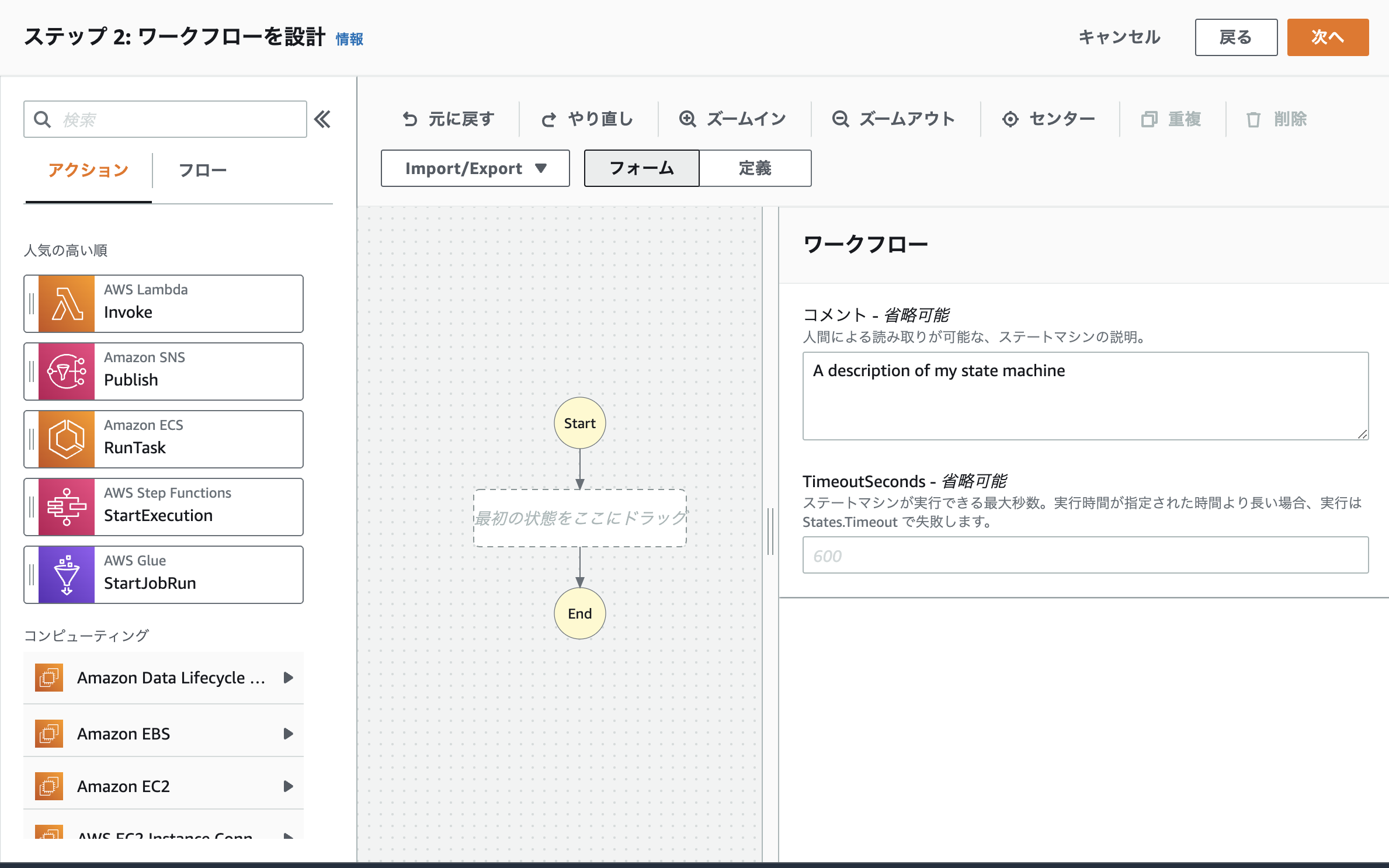
- タイムアウトは初期画面の右側「TimeoutSeconds」にて設定可能です。
今回の処理は時間がそこまでかからないので60秒で設定しています。
ここはシステムの処理に合わせて設定してください。
また、タイムアウトの設定画面は背景をクリックすることで表示されます。
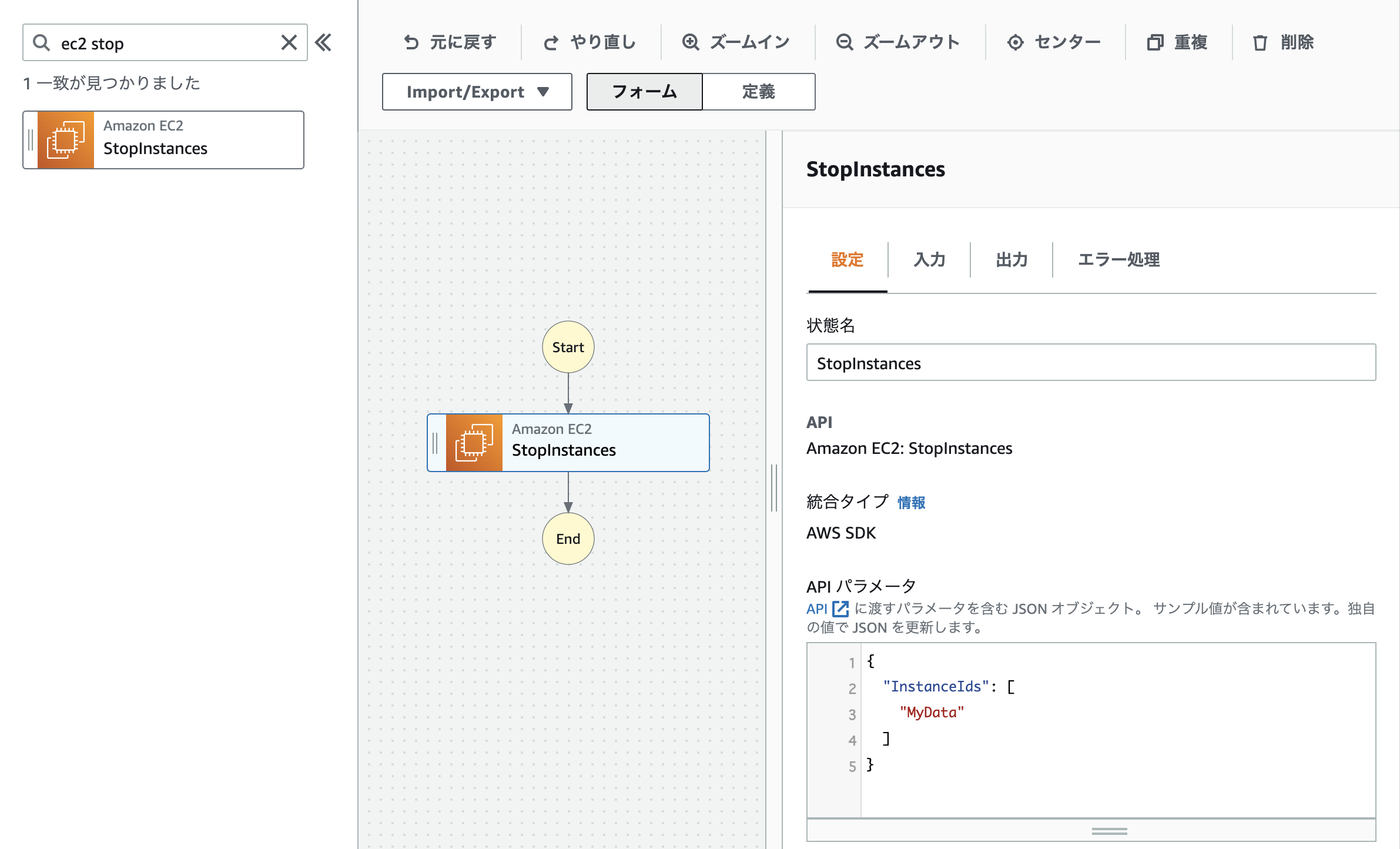
- 次にワークフローにアクションを追加していきます。
今回のシステムはインスタンスを停止させることが目的なので、インスタンスを停止するアクション「StopInstances」を追加します。
「ec2 stop」でアクションを検索すると「StopInstances」がヒットします。
この「StopInstances」をワークフローの真ん中までドラッグするだけで、アクションを追加することができます。
- 次にアクションのパラメータを設定していきます。
アクションのパラメータをJSON形式で設定します。
「StopInstances」はインスタンスを停止するアクションなので停止するEC2のインスタンスIDを設定する必要があります。
アクションごとに何を設定するべきかは公式ドキュメントに記載されているので確認してください。
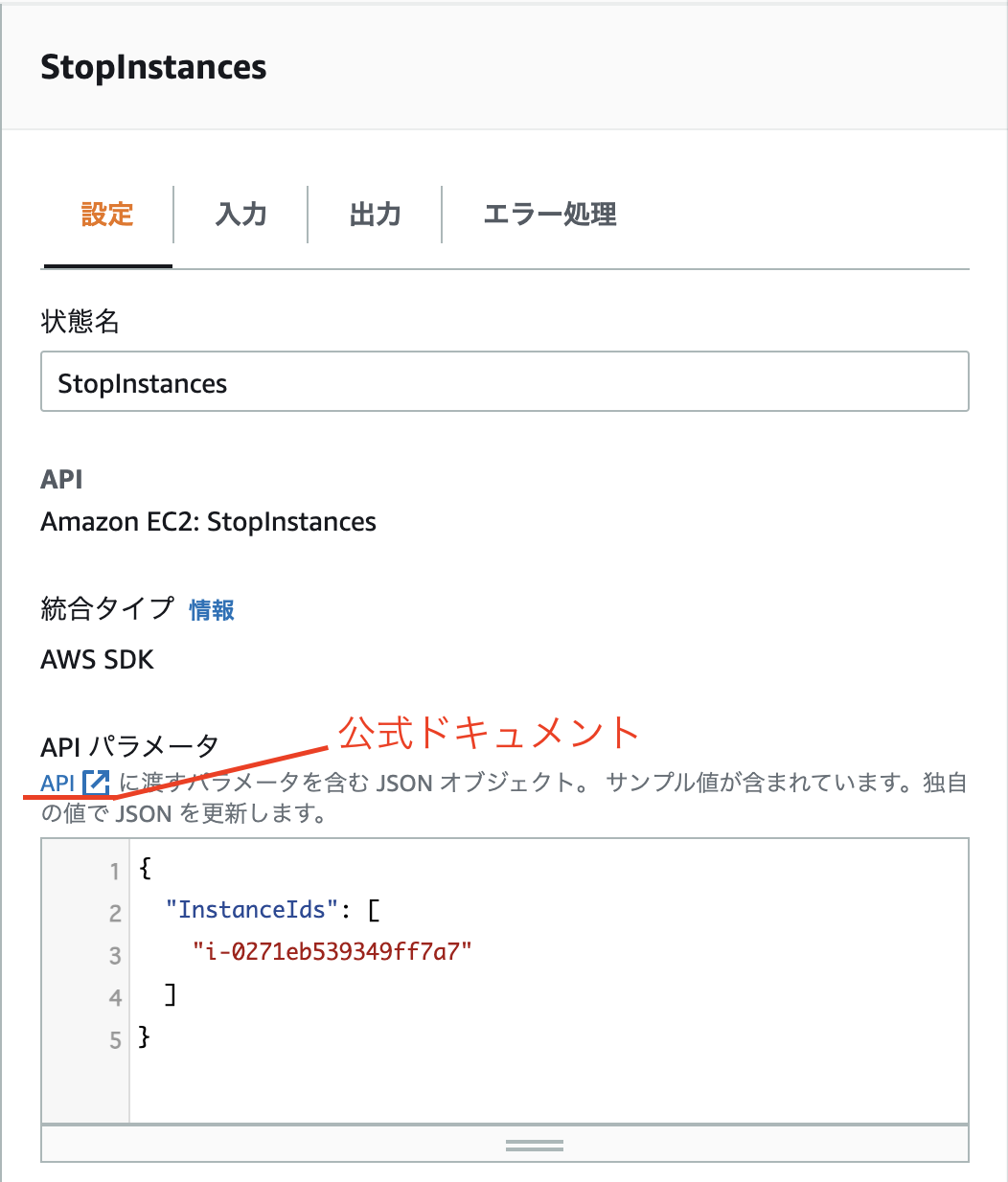 ※公式ドキュメントのリンクがない場合もあります。その場合はアクション名などで調べてください。
※公式ドキュメントのリンクがない場合もあります。その場合はアクション名などで調べてください。
- Step Functionsではこのワークフローをキャンバスに、視覚的に操作するだけで簡単にシステム構築することができます。
-
ワークフローの確認
アクションの準備が整ったので、画面右上の「次に」を押下し、作成したステートマシンを確認します。
画面左側にて先ほど視覚的に作成したワークフローがスニペットで表記されていることが確認できます。
コードでも管理できるのはとても良い点ですね。
確認が終わったら「次へ」を押下します。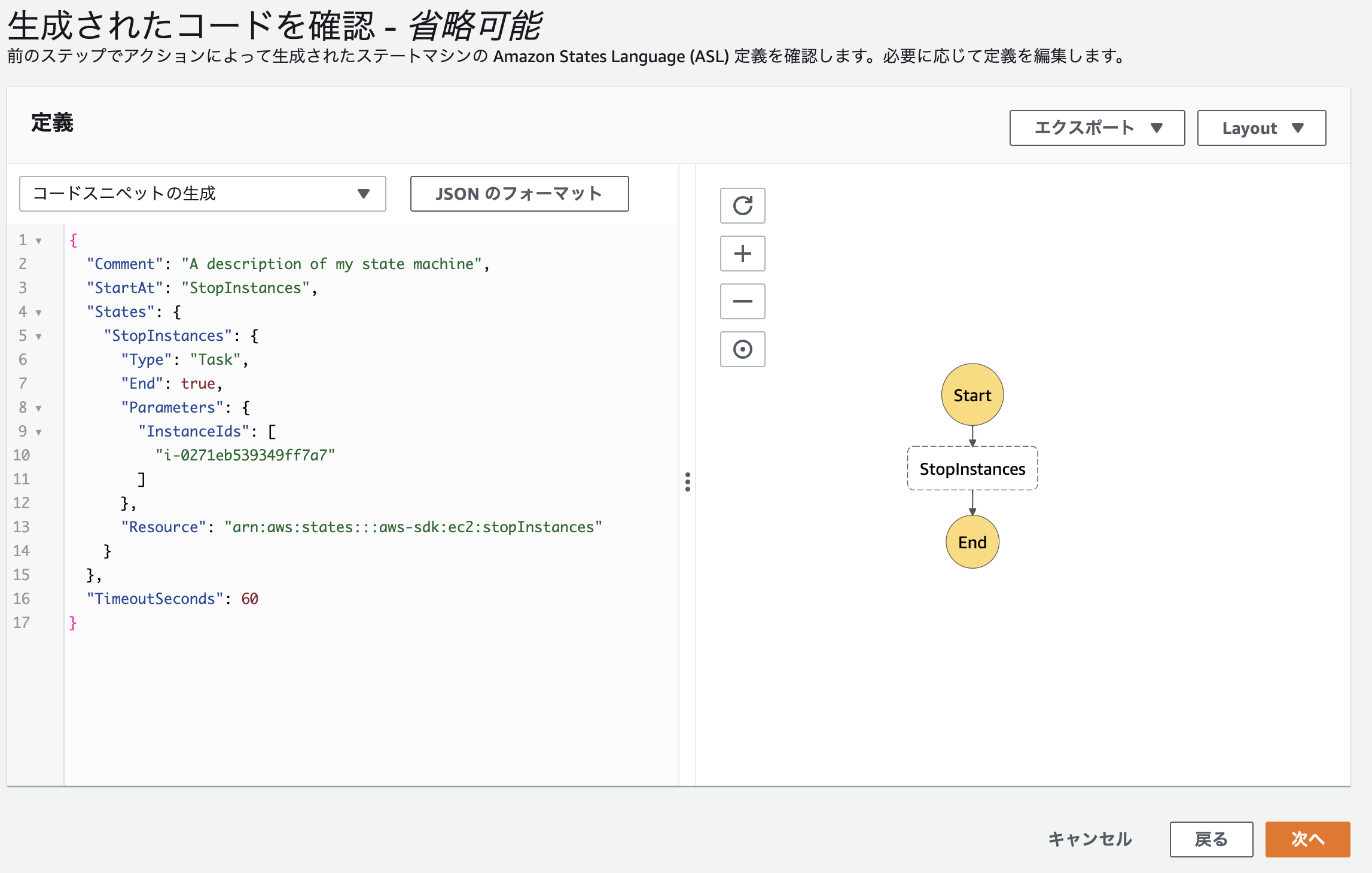
-
ステートマシンの各種設定
次にステートマシンの名前などを設定していきます。
今回は項目「ステートマシン名」に任意の名前(StepFunctions_test)を入力し、 「ステートマシンの作成」を押下します。 -
ロールの設定
今回はEC2の操作を行うため、ロール設定が必要になります。
IAM ロール ARNを押下し、ロールに必要なポリシーを追加しましょう。
今回は「AmazonEC2FullAccess」をアタッチしていますが、必要に応じて適切なポリシーをアタッチしてください。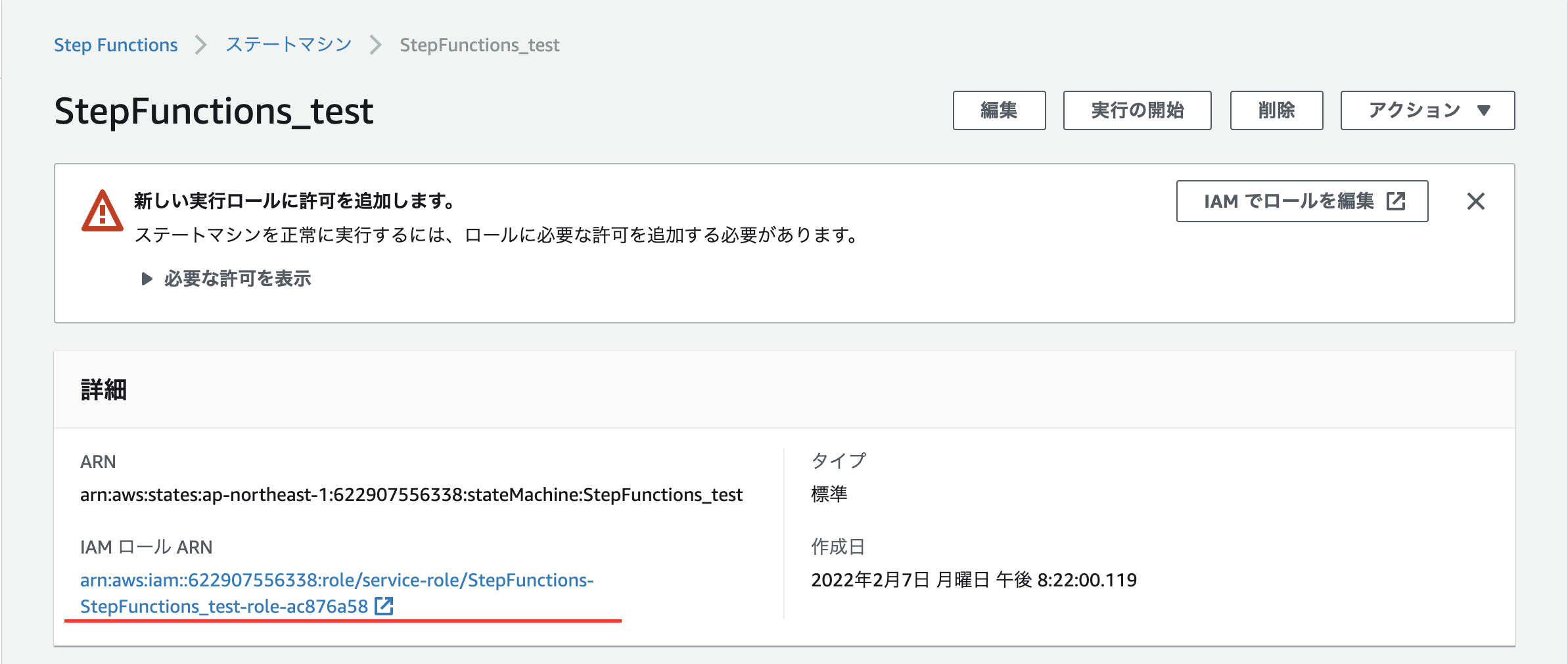
-
実行
あとは「実行の開始」を押下して実行してください。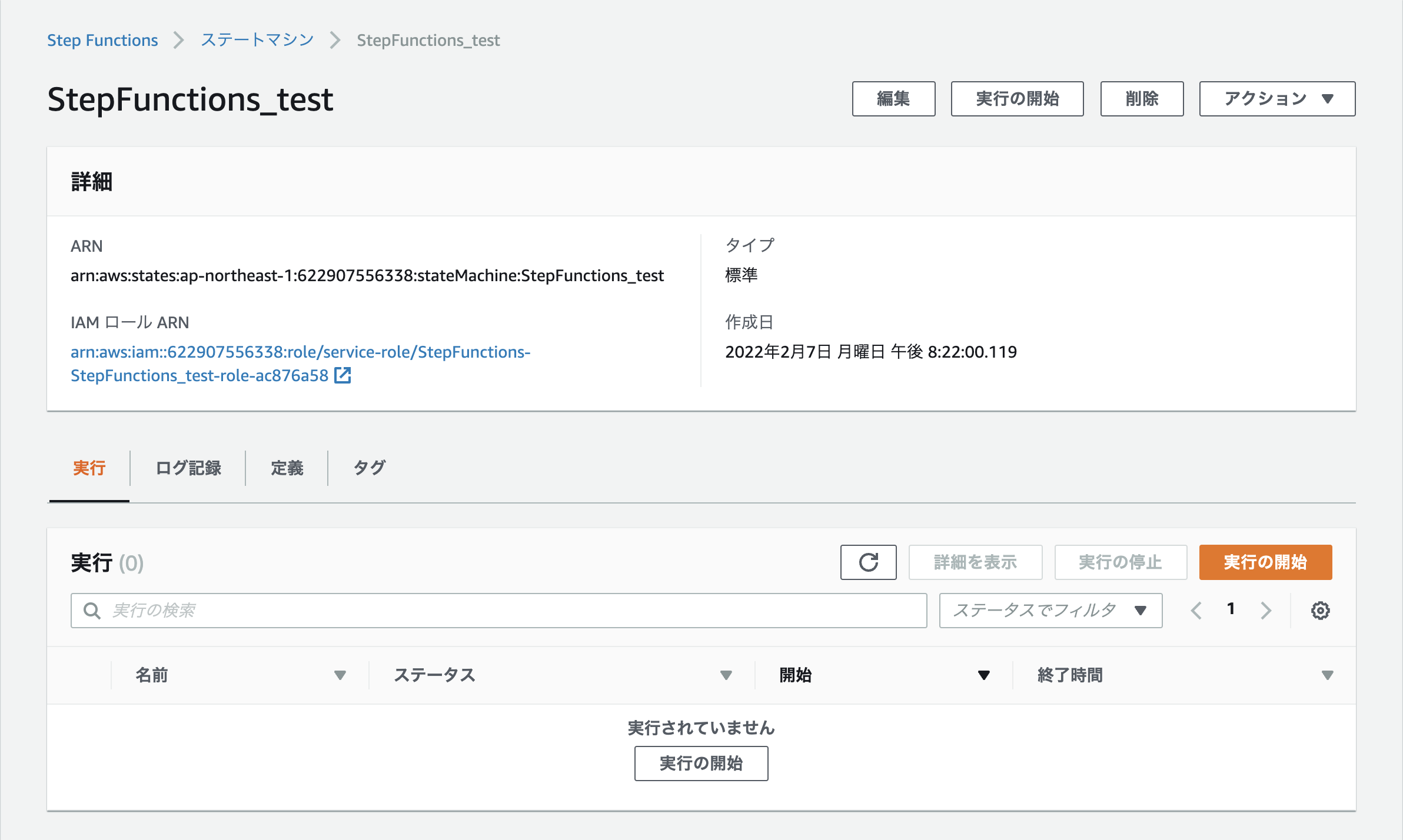 実行完了したらそれぞれのアクションが緑色になります。
実行完了したらそれぞれのアクションが緑色になります。
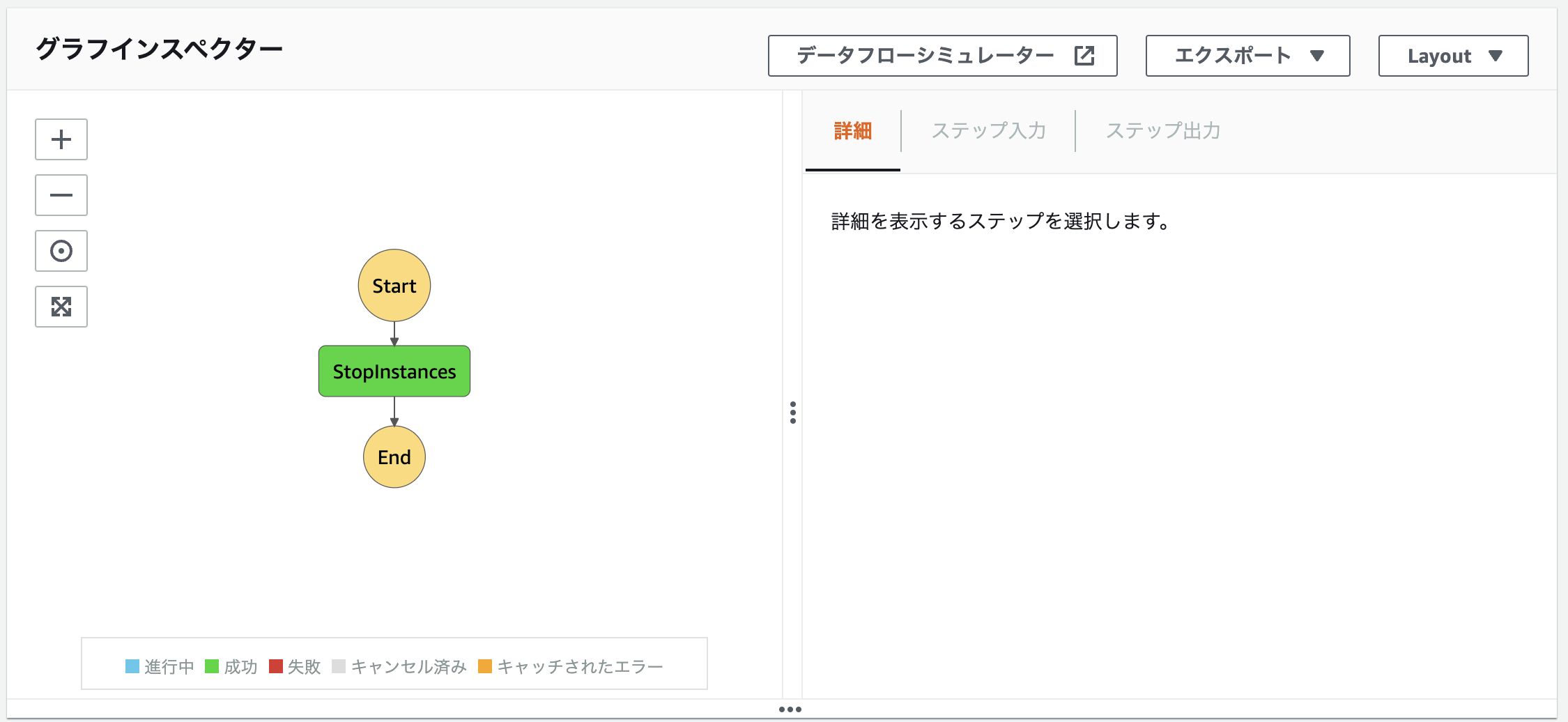 実際に対象のインスタンスを確認すると、インスタンスが停止していることが確認できます。
実際に対象のインスタンスを確認すると、インスタンスが停止していることが確認できます。
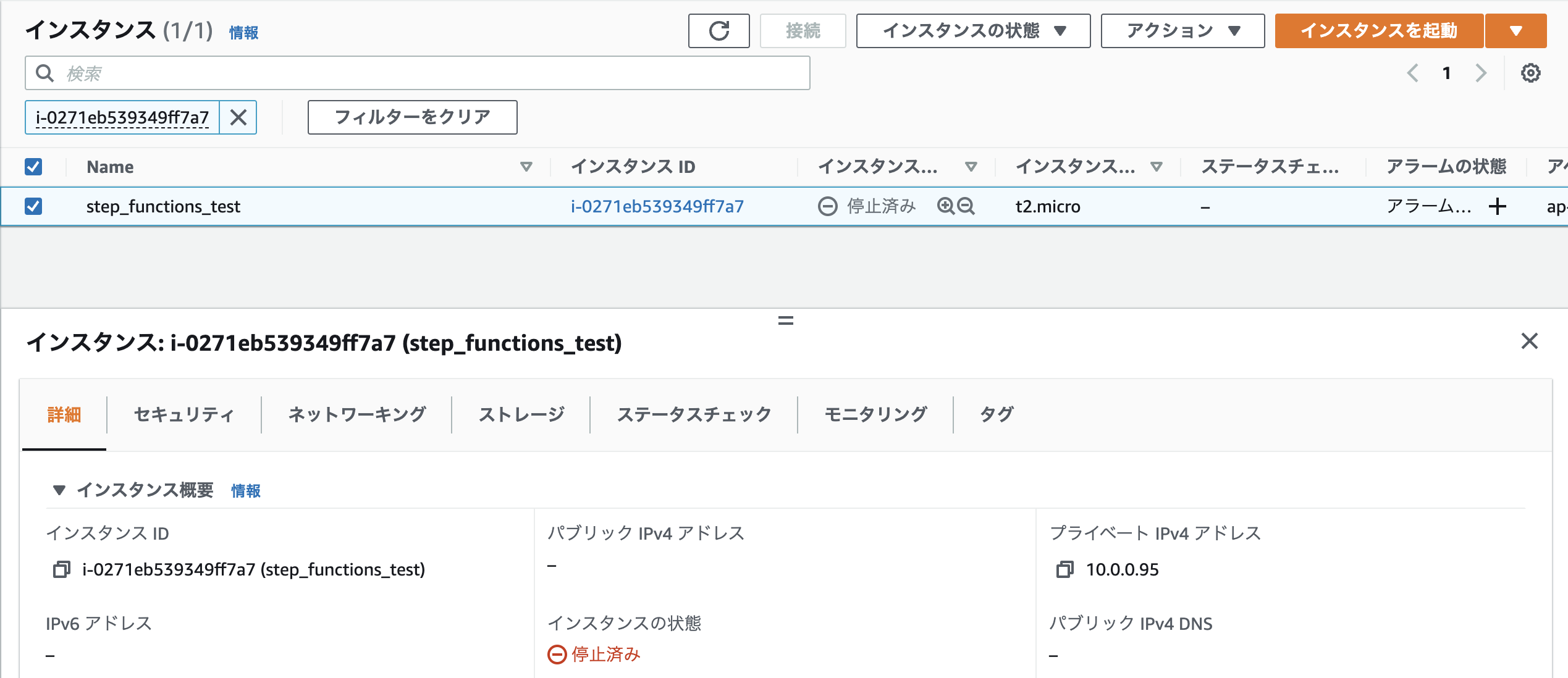 これでステートマシンの作成は完了しました。
これでステートマシンの作成は完了しました。 -
EventBridgeとの連携
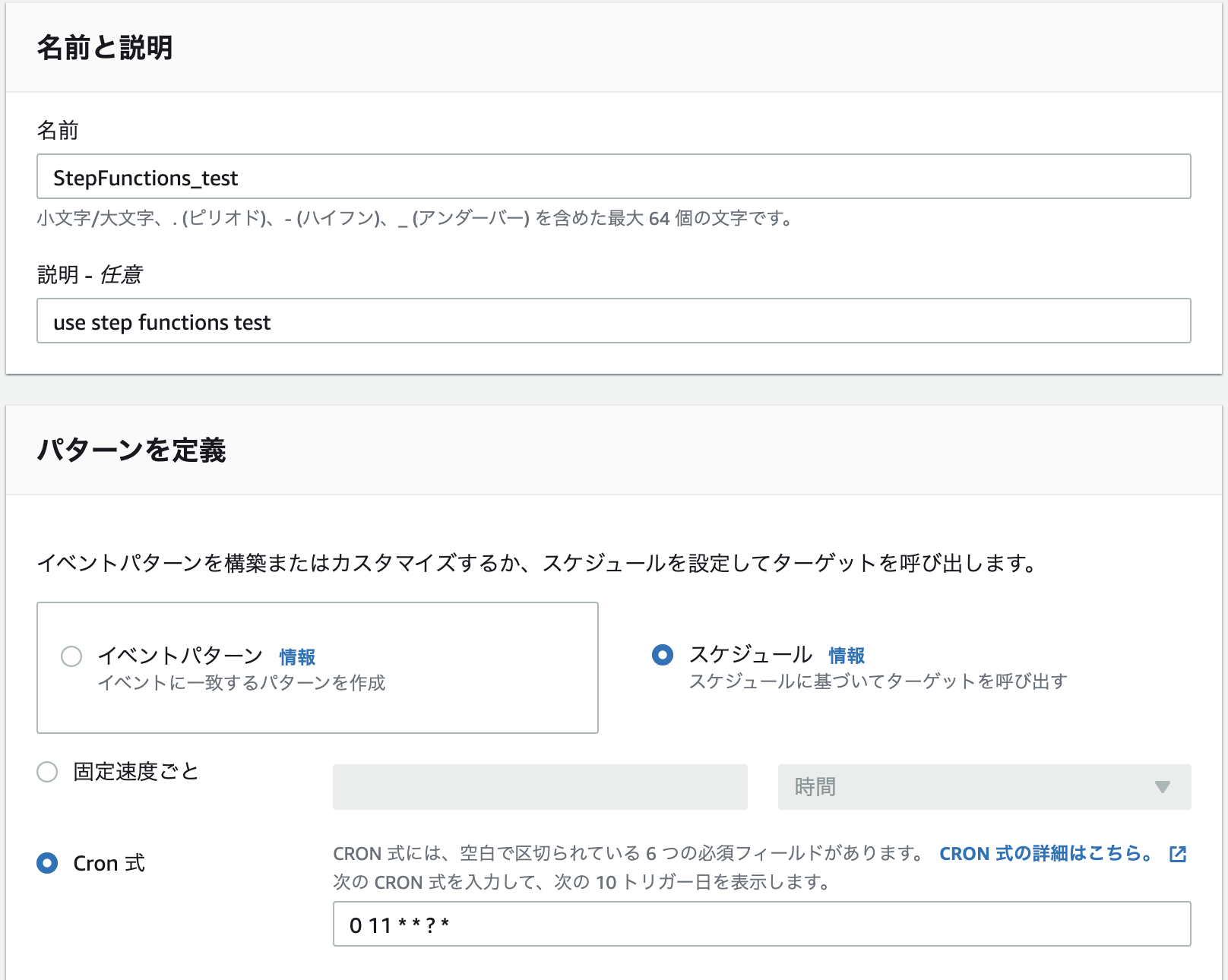
インスタンスを停止するステートマシンが完了したので、次は毎日定時になったらステートマシンを動かすよう、EventBridgeと連携します。
今回は下記のようにEventBridgeのルールを作成しました。
cronはタイムゾーンはUTCであることに注意してください。
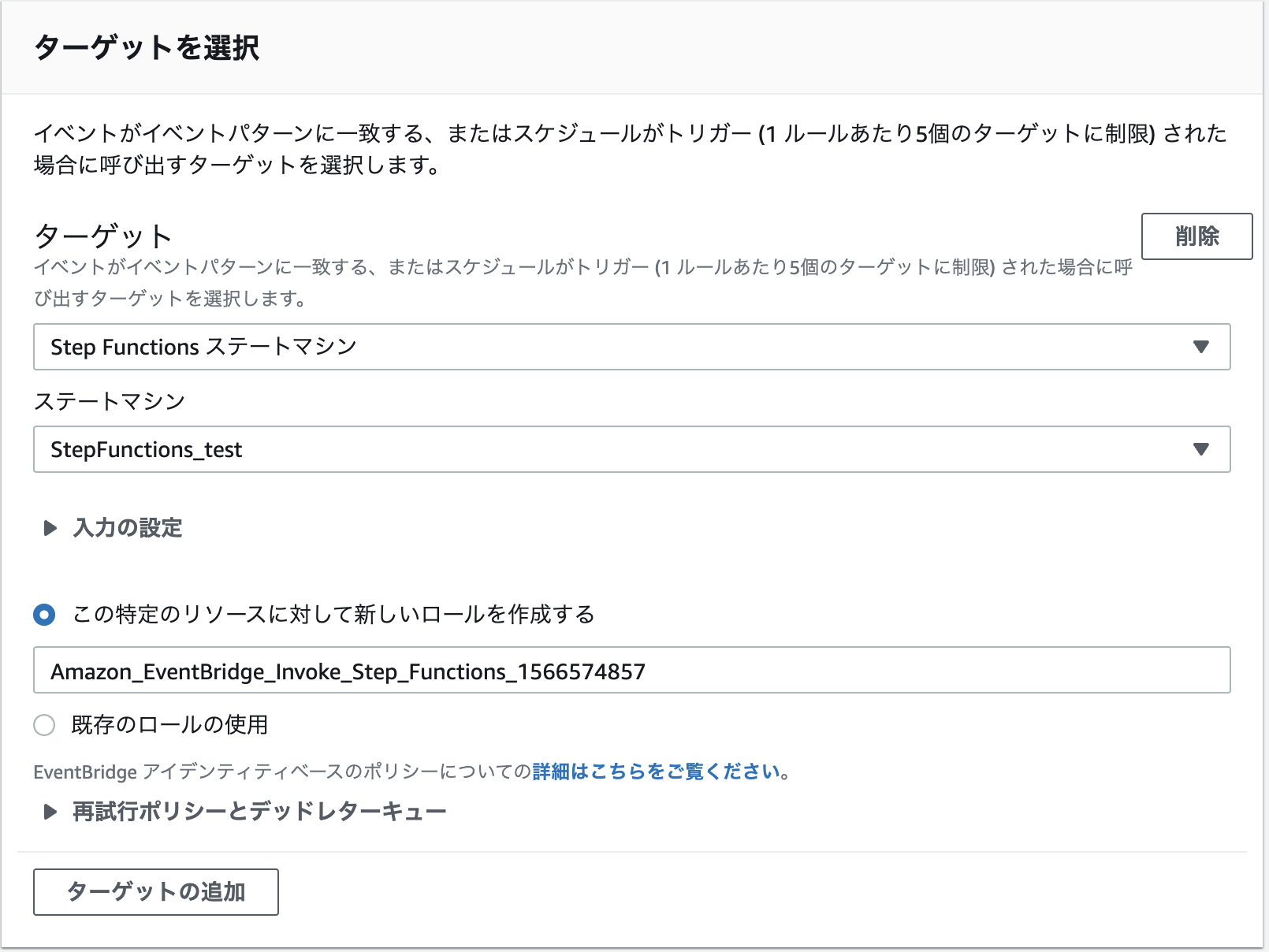
ターゲットには先ほど作成したステートマシンを選択してください。
時間になったらちゃんとインスタンスが停止しているか確認してみてください。
料金
AWS Step Functionsの料金は安く、気軽に取り入れることができます。料金はワークフローのステップが実行される際に発生する状態遷移の回数を元に計算されます。
無料枠は1カ月の状態遷移の回数が4000回/月まで用意されています。
無料枠を超えた分に関しましては、1000回毎に0.025USD加算されていきます。
1日数回程度、実行するバッチのようなものであれば無料枠で抑えられるのがとても良いですね!
今回作成したワークフローの場合、ステップが1つだけ(StopInstancesのみ)なので月あたり4000回まで無料で動かせます笑
AWS Step Functions の料金
まとめ
今回はStep Functionsで簡単にシステムを作ることができました。ワークフローでの構築は楽しく・すぐに完成するので大変良いですね!
ちょっと難しい処理がある場合はlambdaを入れてしまえば解決も難しくないというのもポイント高いです。
今回はインスタンスの停止でしたが、同じように「定時になったらインスタンスを起動する」システムを作ることで、
「勤務時間の間だけ開発環境を稼働させる」といった課題を解決できてしまいます。
これだけでも開発費が大幅に削減できますね。
他にも「Slackなどのチャットツールからデプロイを行う」や「月末にS3にある請求書から売上をまとめる」なんて課題も面白そうです。
みなさんも是非、日頃の小さな課題などをStep Functionsで解決してみてください!
サーバ運用とWebサイト運用・システム運用などが業者が別々で問題解決が困難、もしくは業務をワンストップでお願いしたいなどございましたら遠慮なくご相談ください。
サーバの設計や構築のみなどミニマムな業務からも承ってますので是非コムデへご相談ください。
はじめに
今回は簡単にセキュリティー対策のできるAWSの脅威検知サービスであるAmazon GuardDutyを紹介したいと思います。オンプレミスの時代と比べるとAWSなどのパブリッククラウドでは簡単にサーバーを立てることができとても便利な時代になりました。気軽に利用できるためセキュリティー対策ができてなくマイニングにされたり、高額請求されたなどの話はよく耳にします。
AWS ではセキュリティー対策として下記のような様々なサービスを提供しております。今回はこの中でも簡単始めることのできるGuardDutyについて説明させていただきます!
- ■ GuardDuty
- ■ Amazon Macie
- ■ AWS License Manager
- ■ Config
- ■ CloudTrail
- ■ AWS Security Hub
- etc....
Amazon GuardDutyとは
AWSアカウント、ワークロード、および Amazon S3 に保存されたデータを保護するために、悪意のあるアクティビティや不正な動作を継続的にモニタリングする脅威検出サービスです。悪意のある操作や不正な動作を継続的にモニタリングしてくれます。
機械学習、異常検出、および統合された脅威インテリジェンスを使用することで、潜在的な脅威を識別し、優先順位を付けてくれます。料金
Amazon GuardDutyの利用料金はAWS CloudTrail 管理イベント数、AWS CloudTrail S3 データイベント数、VPC フローログと DNS ログのデータ量に対して課金が行われます。
Amazon GuardDuty の料金
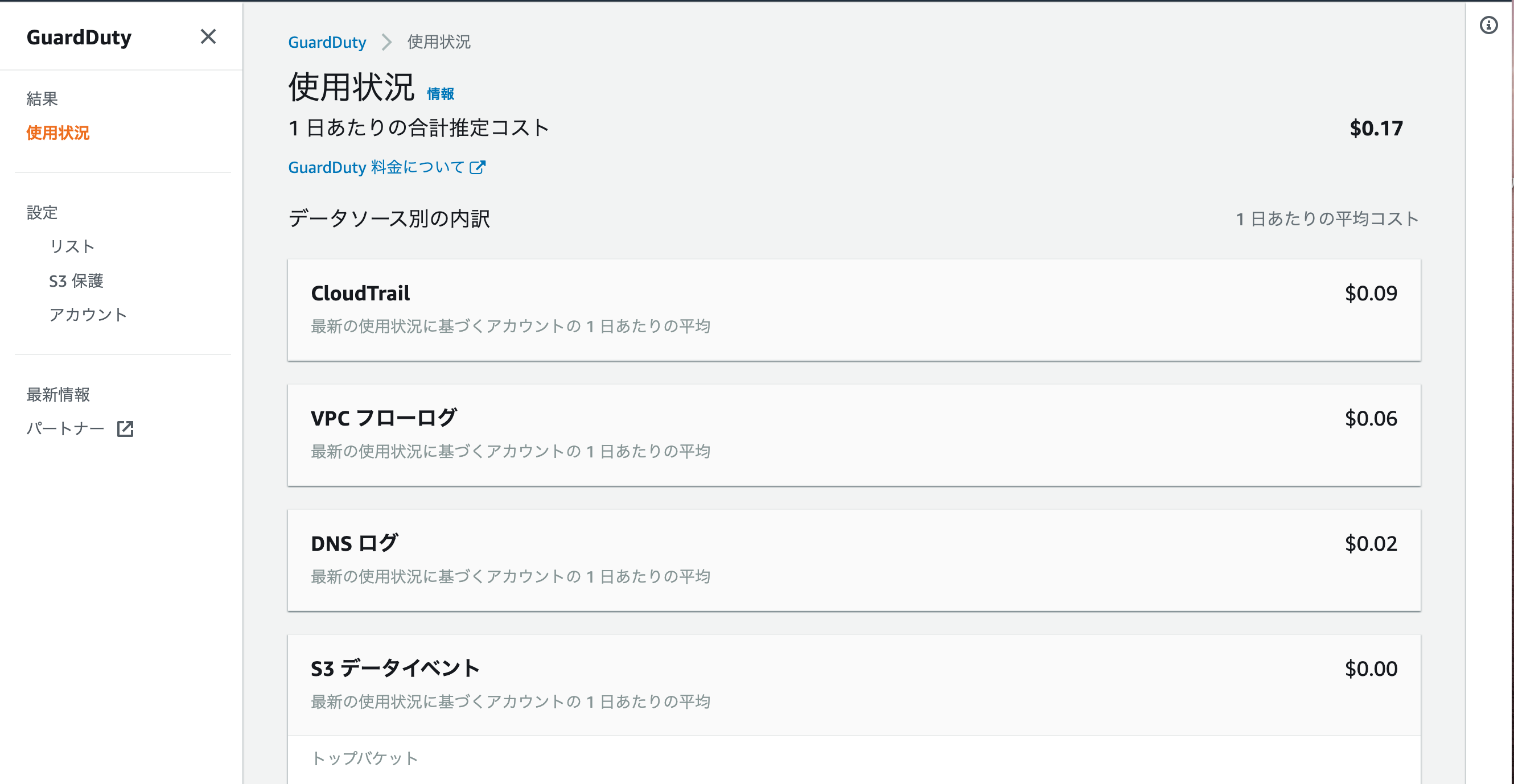
計算はしづらいですがかなり安いです!! また、1日あたりの合計推定コストはGuardDutyのコンソール画面で簡単に確認することができます。
Amazon GuardDutyの設定
GuardDutyはボタン1つで有効化することができ継続的にモニタリングをしてくれるため利用者側としては特に何もする必要はありません。しかし、注意していただきたいのはGuardDutyは攻撃や異変を検知するだけでその後の対応・対策はしてくれません。
また、Cloudwatchevent と SNSを連携することにより異変検知したらセキュリティー担当者へメールを送信させることができます。
手順はすごく簡単です。
- 1. Amazon GuardDutyを有効化にする
- 2. SNSトピックを作成する
- 3. Cloudwatchイベントを作成する
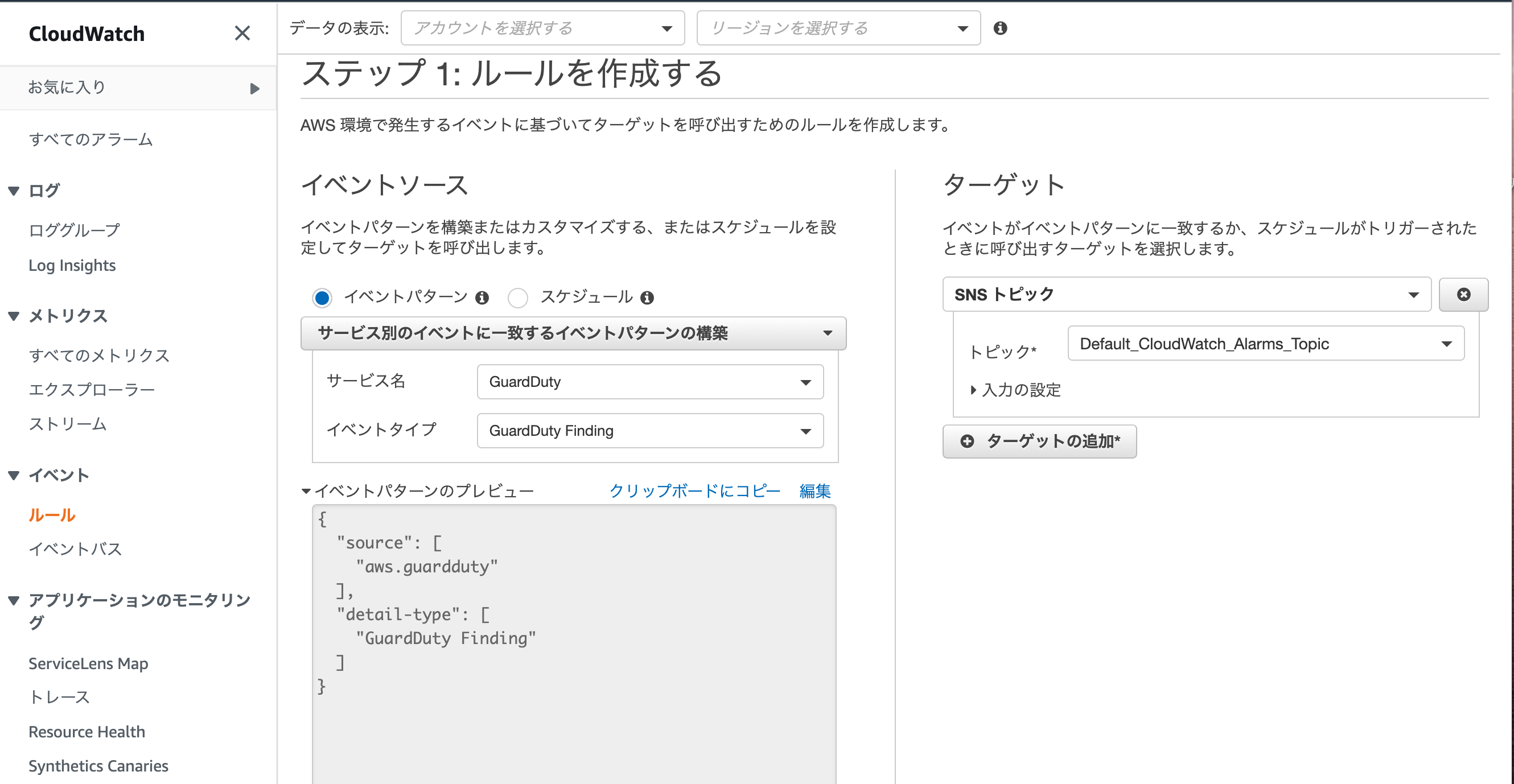 これでAmazon GuardDutyが検知したときにメールを送信してくれるようになります。
これでAmazon GuardDutyが検知したときにメールを送信してくれるようになります。
まとめ
Amazon GuardDutyはボタン一つで有効化することができ利用料金も比較的安いので全アカウント全リージョンで有効にすべきだと思います。
また、まだ利用されていない方は最初の30日間は無料で利用できるので是非試してみてください!
サーバ運用とWebサイト運用・システム運用などが業者が別々で問題解決が困難、もしくは業務をワンストップでお願いしたいなどございましたら遠慮なくご相談ください。
サーバの設計や構築のみなどミニマムな業務からも承ってますので是非コムデへご相談ください。
lego --accept-tos \ --path=/etc/letsencrypt \ --email="email@example.com" \ --dns="route53" \ --domains="www.example.com" \ run
lego --accept-tos \
--path=/etc/letsencrypt \
--email="email@example.com" \
--dns="route53" \
--domains="www.example.com" \
renew \
--days 30CDKとは
AWS クラウド開発キット (AWS CDK) は、使い慣れたプログラミング言語を使用してクラウドアプリケーションリソースを定義するためのオープンソースのソフトウェア開発フレームワークです。 出展:https://aws.amazon.com/jp/cdk/AWS CDK(以降CDKに省略)はソースコードでインフラ構築・管理を行うフレームワークです ソースコードによるインフラ構築であればCloudFormationも候補に上がりますが、 CloudFormationの場合、ソースコードとしてjsonファイルもしくはyamlファイルに論理名の紐付けなど細かく記載する必要があります。 しかし、CDKの場合はTypeScritp、Python、Javaなど普段使い慣れたプログラム言語を使用することができ、細かい設定はCDKが吸収してくれるため、実装負荷が大変少ないです。
CDKで変わったインフラ構築
これまではAWSのコンソール上からインフラを構築していました。 しかし、コンソール上から手作業でインフラを用意するのは下記のこともあり”とても”大変です。- 構築に時間がかかる インフラ構築にはVPC、EC2、RDSなどさまざまなものを構築する必要がある それぞれ人の手で行うと一つの環境を作るのに数時間掛かってしまう
- 構築ミスが発生 人の手による作業なので当然構築ミスも発生する 当然、ミスが出た際の問題解決に時間が割かれてしまう
- 殆ど同じ環境を作らなければいけない苦行 web開発では通常、 PROD,STG,DEV+α環境と多くの環境を作ることが求められる。 そのため、同じ作業を複数回行わなければならず、マラソンをやっているような気持ちになる ※こちらとても私的な意見です
CDKのソースコードがあれば短時間でインフラ構築が完了する
CDKではソースコードさえあればターミナル上で片手で数えられるコード入力のみでインフラの構築が済んでしまう 例えば、下記のコマンド一発でソースコード記載のインフラ構築ができてしまいます。cdk deploy --allミスが少なくて済む
ソースコードを読み込んでインフラ構築を行うため、いつでも同じ環境を作成することができる 属人化を防ぐ意味でも良いですね また、CDKはライブラリを使用するため、エディタの補完機能を使用することができ、ソースコード作成時のミスも少なくて済みます。バージョン管理ができる
CDKはソースコードでインフラ構築ができるため、gitなどでバージョン管理ができます 下記のコマンド一発でソースコード記載のインフラ環境と実際にインフラ環境の差分が表示されますcdk diffCDKはいいぞ
CDKは便利の一言です 一度ソースコードを組んでしまえば同じ環境をいくらでも量産できるので、ちょっと新しい環境を作って試してみたいことがあった際に簡単にスクラップ&ビルドを行えてしまいます。 開発速度の向上が期待できますね。 また、インフラ構築自体はコマンド一発で出来上がってしまうので、属人化しないのが非常に良いですね。極論を言ってしまえば、ソースコードさえあればサルでもインフラ構築ができてしまいます。 問題のソースコードの実装自体は慣れさえすれば簡単です。特にAWSを使用したことがある方であれば構築時の設定と同じ内容を記載すれば良いので、すぐに感覚が掴めると思います。 一度触ってしまったらコンソール上でのインフラ構築には戻れません CDKにはそれほどの魅了が詰まっています 初心者用にAWSがワークショップを作ってくれているのも敷居が低くて大変良いです 皆さんも是非機会がありまたら触ってみてください!実装手順
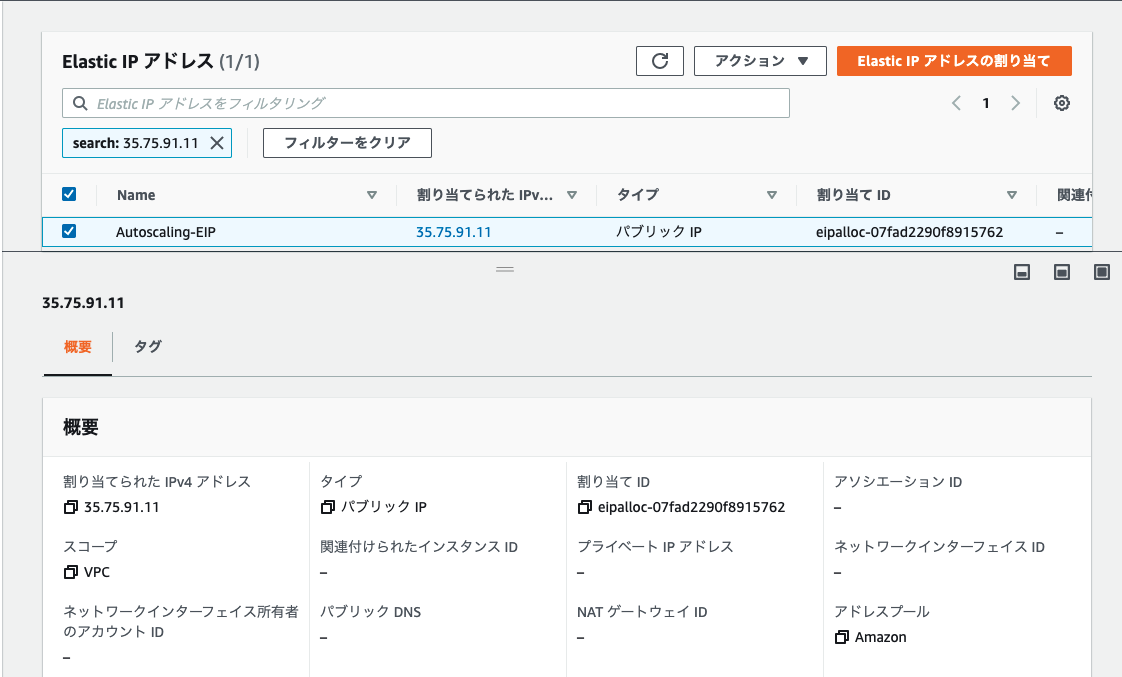
- 1. アタッチさせるEIPを事前にプールしておく
- 2. IAMポリシーの作成
- 3. シェルスクリプトの設定
- 1. アタッチさせるEIPを事前にプールしておく
- 2. IAMポリシーの作成
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ec2eip",
"Effect": "Allow",
"Action": [
"ec2:CreateImage",
"ec2:CreateSnapshot",
"ec2:Describe*",
"ec2:DescribeInstances",
"ec2:DescribeAddresses",
"ec2:AssociateAddress"
],
"Resource": [
"*"
]
},
{
"Sid": "ec2",
"Effect": "Allow",
"Action": [
"ec2:RebootInstances",
"ec2:StartInstances",
"ec2:StopInstances"
],
"Resource": [
"arn:aws:ec2:ap-northeast-1::instance/"
]
}
]
}- 3. シェルスクリプトの設定
#!/bin/bash
yum install jq -y
# EIPの割り当てID
eip_alloc_ids="eipalloc-07fad2290f8915762"
export AWS_DEFAULT_REGION=ap-northeast-1 instance_id=$(curl -s http://169.254.169.254/latest/meta-data/instance-id)
available_alloc_id=$(aws ec2 describe-addresses --allocation-ids ${eip_alloc_ids} | jq -r '[.Addresses[] | select(.InstanceId == null)][0] | .AllocationId')
echo $available_alloc_id
aws ec2 associate-address --instance-id ${instance_id} --allocation-id ${available_alloc_id}